-
C clareqiaoposted in Research blogs • read more
LIU Jialong, PhD candidate in Leiden University
Ever since 2017, I have been participating in a project, chaired by Professor Hilde De Weerdt with the assistance of Xiong Huei-lan, the aim of which is to use digital approaches to investigate the history of construction in imperial China. We have selected the construction of city walls 城墻 to do a pilot study. In our research, an important step is to use MARKUS to mark up the information we want to analyze in local gazetteers (for a discussion of how to mark up and extract data with regular expressions in MARKUS, see Xiong Huei-lan’s post). The first step in this process is to identify and import or upload relevant primary source texts. In this post, I discuss where we can access relevant sources from local gazetteer databases.
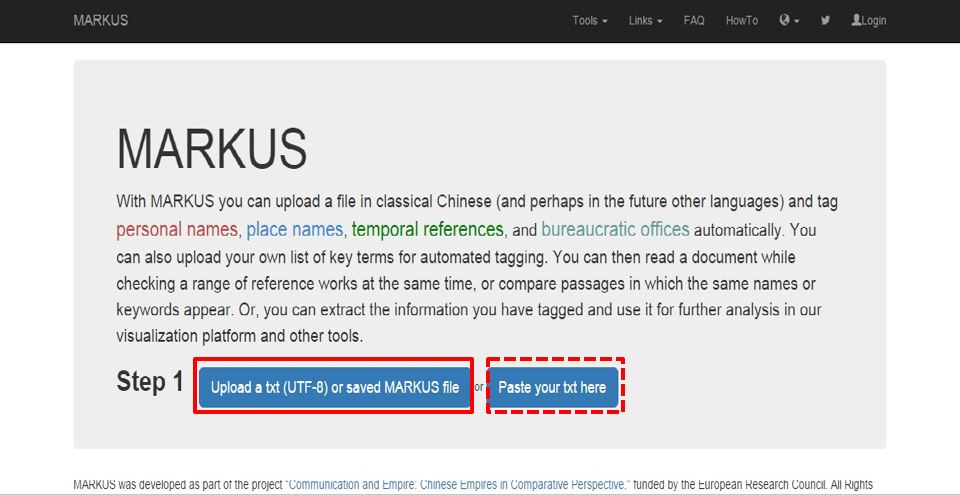
Before acquiring texts from databases, we should evaluate them. It is necessary to be fully aware of the advantages and shortcomings of different databases. For example, how many gazetteers are included in a database? Can we browse the content of gazetteers? Can we download texts? Can we double check the original images in the database? What retrieval strategies are offered by a database? Does a database provide useful tools? In the following, I will briefly introduce select Chinese local gazetteer databases that are commonly used based on my own experience.
-
10,000 gazetteers will be included and 4000 of them are available
-
users can easily browse the content and compare the full text to original images of the titles included
-
texts can be download (to use MARKUS, save downloaded content as a .txt file)
-
full-text retrieval is available

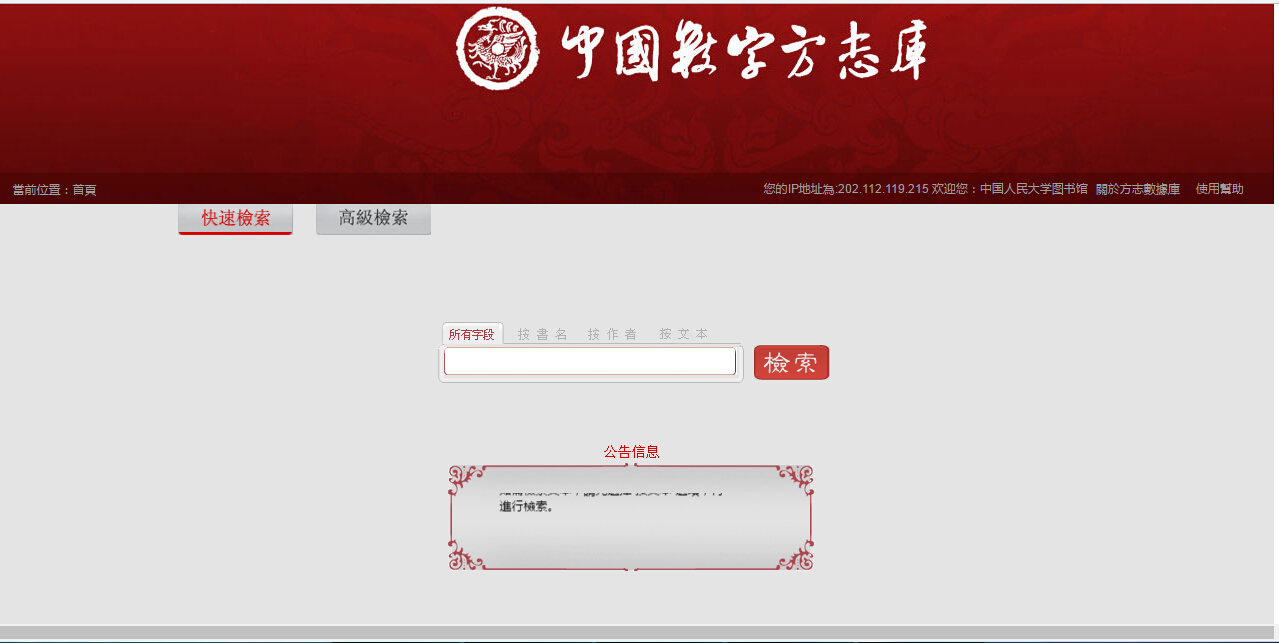
(2) Zhongguo shuzi fangzhiku 中國數字方志庫
-
11,000 gazetteers are included (This makes this the largest classical Chinese local gazetteer database I have used. Two examples: In the case of Chongming County 崇明, 中國數字方志庫 includes 6 gazetteers for different periods, whereas 中國方志庫 has 4. The latter misses two editions in 雍正 (1723-1735) and 民國 (1912-1949). In the case of Taicang Prefecture 太倉, 中國數字方志庫 has 8 gazetteers, whereas 中國方志庫 has 5. The latter misses two editions in 光緒 (1875-1908) and 宣統 (1909-1911), and an undated manuscript named 太倉衛志.)
-
users can browse the content and have the access to original images of books
-
texts can be downloaded
-
full-text retrieval is available (However, users cannot search gazetteers based on region. By contrast, 中國方志庫 provides such a retrieval strategy.)
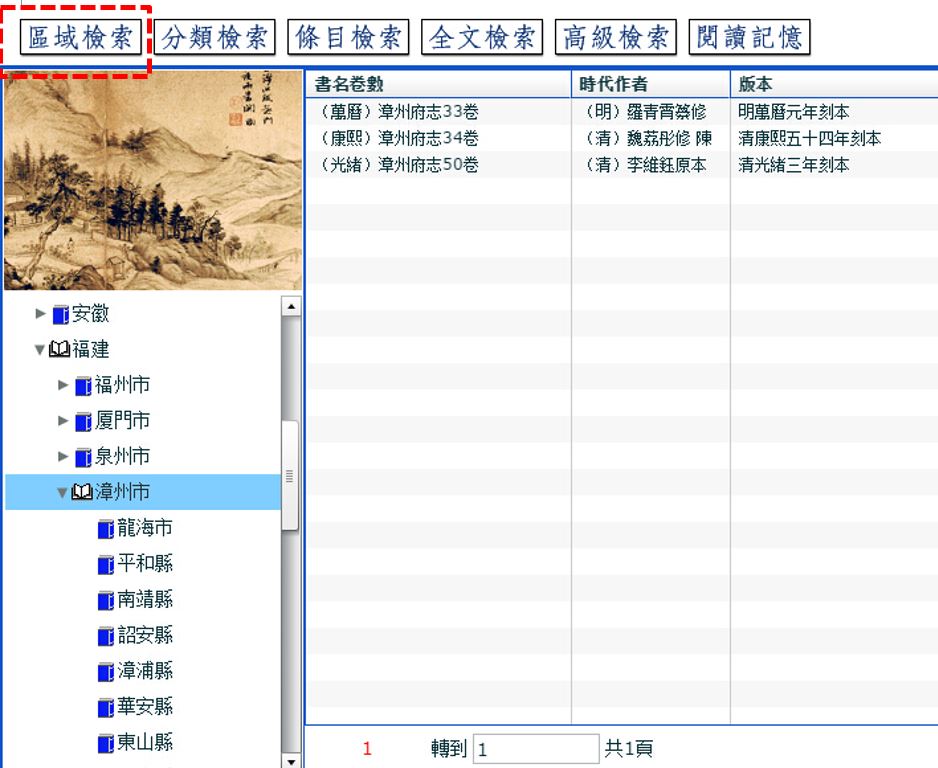

- the interface of 中國數字方志庫 is not as user-friendly as that of 中國方志庫, especially regarding the reading experience of the full text in font and layout

中國方志庫
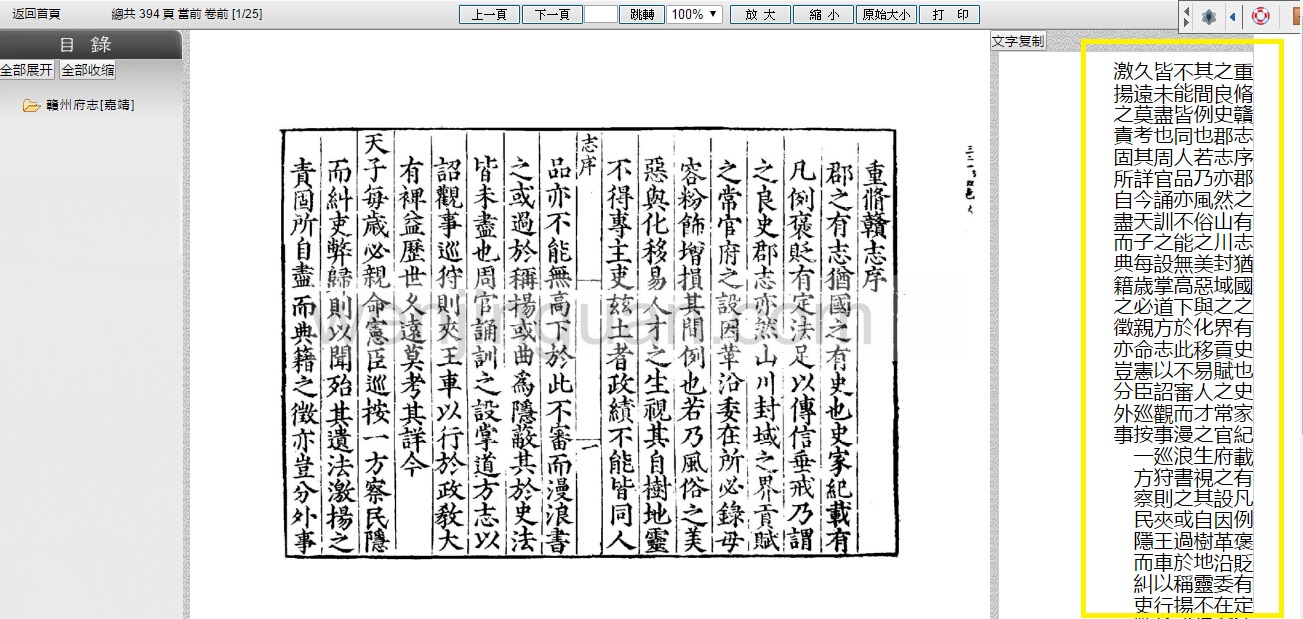
中國數字方志庫
(3) Xin fangzhi 新方志
-
40,000 gazetteers are included (It only covers gazetteers compiled after 1949.)
-
users can browse the content and directly read the original texts in PDF format
-
users can download the PDF files
-
full-text retrieval is impossible (search results are limited to chapters.)
-
includes 6000+ gazetteers compiled before the end of the Qing Dynasty held by the Chinese National Library
-
users can browse the content but the website often crashesusers can browse the content but the website often crashes
-
users can read the scanned images of gazetteers but cannot download texts
-
full-text retrieval is not available
(5) Zhongguo dalu ge sheng difangzhi shumu chaxun xitong 中國大陸各省地方志書目查詢系統
-
a catalogue developed by Academia Sinica in Taiwan covering local gazetteers compiled both before and after 1949
-
users cannot browse the content of gazetteers

(6) Regional databases set up by regional libraries
This kind of database usually includes the local gazetteers in one region no matter when they were compiled. Below I use Beijingshi shuzi fangzhi guan 北京市數字方志館 as an example:
-
all the local gazetteers about Beijing are claimed to be included
-
PDF versions of gazetteers (scanned images of books) are offered online for users to browse
-
texts cannot be downloaded
-
full-text retrieval is unavailable
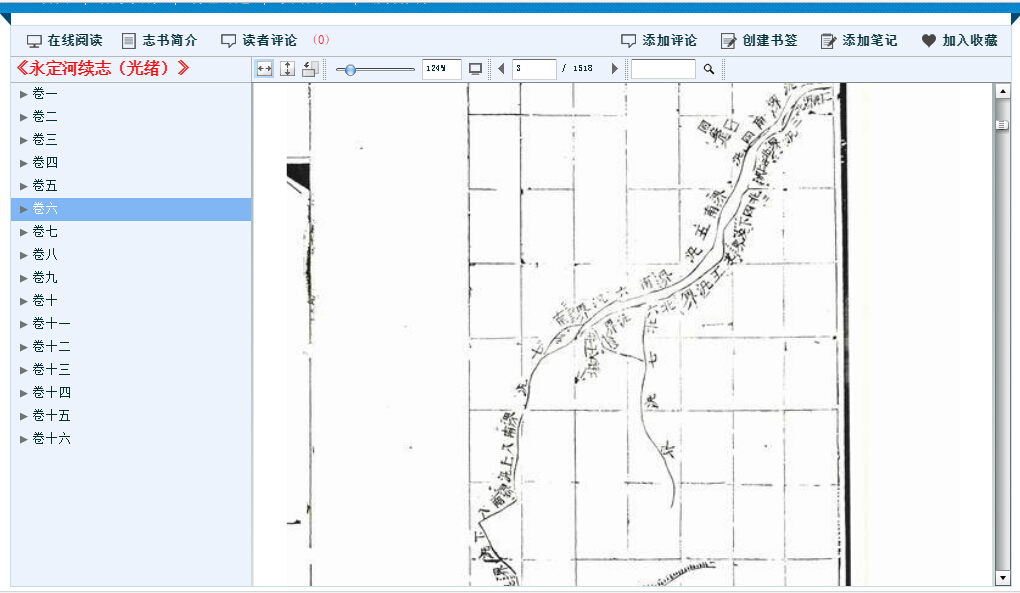
Before uploading texts acquired from databases to MARKUS, we should clean the digital text. When doing so, we should pay attention to blank spaces. In the texts acquired from 中國方志庫, blank space is used to indicate notes 注 in the original text. Such features can be used to, for example, mark up notes in MARKUS.
Variants of Chinese characters 異體字 should also be paid special attention to as they can influence the results of mark-up in MARKUS. I would advise to standardize all variants. If you cannot recognize a variant of a character, you can refer to the dictionary provided by 中國方志庫 or a professional online dictionary for variants specifically, 異體字字典 . (Xiong Huei-lan also describes the difficulty caused by variants when using regular expressions in her post.)
Depending on the quality of the OCR, there may be missing characters or wrong characters in the texts you acquired from electronic databases. When cleaning the text, such problems should be addressed. After cleaning your texts, upload them to MARKUS and explore them with the variety of functionality provided by the platform.
-
-
C clareqiaoposted in Research blogs • read more
[This follows from “The Uses of Digital Philology in Tang-Song History – Part 1”.]
ON BECOMING A CO-DEVELOPER
It was the latter insight that motivated my involvement in designing MARKUS, a text analysis and reading platform for classical Chinese. When applying for a research grant to study political communication in Song history, I decided to include a fulltime postdoctoral position in computer science whose main responsibility would be to help develop methods for visualizing and analyzing communication networks on the basis of the annotation of private records such as notebooks and letters. As this project (2012-2017) draws to a close, I can now say that I am happy I made the decision to invest a substantial amount of time and resources into its digital research component. Historians usually outsource the creation of a website, database, or digital platform for their projects to internal or external parties. Such parties typically spend a limited (and difficult to schedule) amount of time on the project and tend to apply template solutions to the questions posed by their clients. By collaborating with a fulltime computer scientist with an interest in humanities scholarship I was able to begin to address some key problems in the larger environment of Chinese digital scholarship which I faced in my initial work on Huizhu lu.
First, as I discussed at greater length elsewhere, the leading commercial publishers of databases of pre-twentieth-century Chinese materials provided historians with large textual repositories since the early 1990s, but they have made little or no effort since to provide data discovery, visualization or text analysis tools that would allow us to better exploit the digital medium for research purposes. They continue to provide rather basic search functionality, outdated results management, limited and poor reference tools, and unacceptable limitations on the export of search results and the texts included. At a time when researchers should be able to collect and work with materials across vast and expanding textual archives, database design is still steering them to limit their search by genre, author, title, or, in the case of local gazetteers, by place. The packaging of text collections in separate databases has furthermore led to the proliferation of databases; the absence of interoperability has made it difficult for researchers to create collections of texts across different databases with which to do their work.
A second set of problems relates to the limitations imposed by software designed to give researchers better control over the texts they have gathered and the notes they have taken. When evaluating different methods to annotate notebooks and letters and research political communication, I first tried out commercial software designed for social scientists (qualitative analysis software) and then moved on to manually encoding files. The former included convenient tagging and visualization functionality, but commercial software suffered from a) a lack of interoperability with external databases (in our case CBDB or CHGIS); b) the absence of advanced export functionality which made exported results unreadable and unusable in other software; c) the use of propriety file formats which made sharing difficult and sustainability a concern; d) initially, but this is getting better, they were also ill suited for East Asian languages. Manually encoding files in standard formats such as TEI resolves these issues but proved to be somewhat inefficient (due to the repetitiveness of actions that could be automated) and visually unappealing to many students and researchers (due to the basic editor interface).
With Brent Hou Ieong Ho, whom I was fortunate to hire as a postdoctoral fellow in Chinese Digital Humanities, I set out to first generalize the methodology I had developed for encoding notebooks. By developing automated encoding for personal names, place names, official titles, and time references on the basis of CBDB, we were providing a service that offered better discovery and analysis functionality than standard databases and we were doing so in a way that was more efficient than manual encoding.
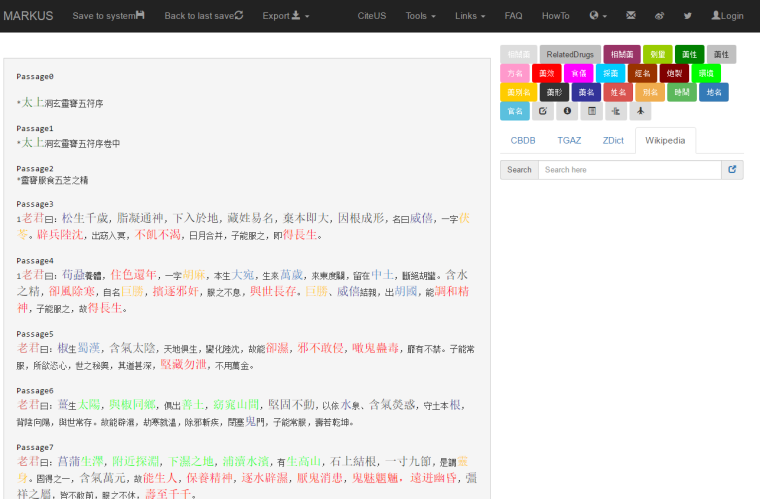
As we worked on this, we kept adding new functionality and designing the platform in ways that modeled the research flows of the historians and humanities scholars working with it. We added manual markup to allow not only for the correction and addition of default tags, but also to give researchers more freedom in defining tag types. We added dictionaries because the platform was not only used to tag and analyze tags but also to read through texts (figure 3). By adding language and domain-specific dictionaries, readers can simultaneously gain access to a wide range of standard reference works. We added a note feature, so that readers can translate, make notes, or leave to-dos for example for items that require further checking in print resources. We added keyword markup so that researchers can upload their own lists of terms to be tagged, and use advanced features such as regular expressions, KWIC, or a keyword generator (which produces keywords appropriate to the uploaded text based on a frequency analysis of the patterns in which one or more selected keywords occur) to analyze their texts. We added filtering options so that tags can be used to select passages that fit one or more criteria.
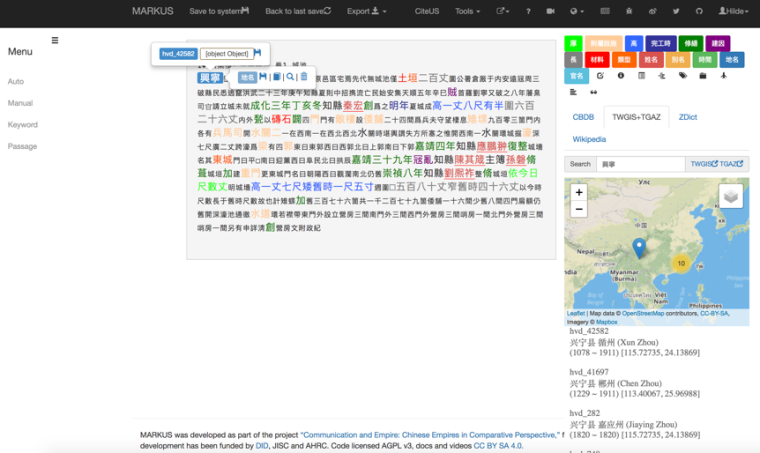
Figure 3: MARKUS platform showing an example of tagging and reference options as well as the option to add gazetteer ids to place names which can be used to map place names after exporting MARKUS files to DOCUSKY. Credit Xiong Huei-lan.
And, we continued to work on simplifying the many steps of extracting tagged passages, merging them with external databases, and then visualizing the combined data in separate packages. In the course of two years we developed MARKUS into a linked platform in which a large part of the annotation and visualization can be undertaken automatically. By linking files saved in MARKUS to Palladio (Humanities and Design, Stanford University) and PLATIN (Max Planck Institute for the History of Science) researchers can, via the VISUS interface, import biographical information linked to tagged names from CBDB and then explore it, alongside their own data, in maps, network diagrams, tables, timelines, pie charts, or tagclouds (Figures 6-8). More recently, we have added functionality to allow for the batch tagging (any number of tags to any number of files) and export of multiple files. Batches of MARKUS files can now be directly exported to DOCUSKY and DOCUGIS platforms (Hsiang Jieh and Tu Hsieh-chang et al., National Taiwan University) where they can be transformed into a textual database (XML) and where further text and spatial analysis of the text and tags can be undertaken (Figures 2 and 4). They can also export all data for more sophisticated analysis in more specialized spatial, network, or statistical packages. To improve access to texts and facilitate importing, we have also been linking to MARKUS from commonly used open access textual repositories such as Donald Sturgeon’s [Chinese Text Project](file:///Users/jqiao/Desktop/jobs/7 digital philology/ctext.org) and Christian Wittern’s Kanripo.
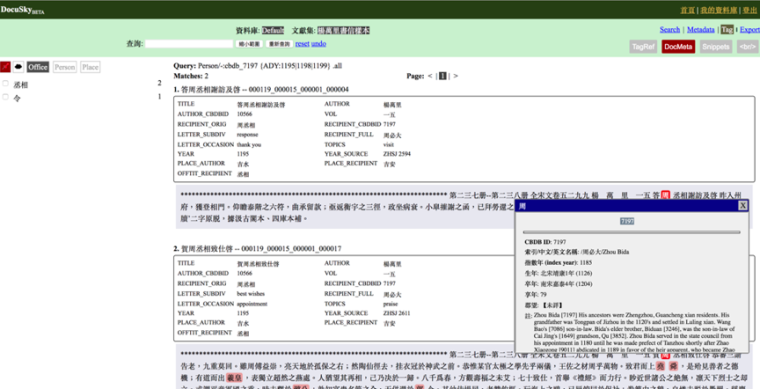
Figure 4A. Sample of Yang Wanli’s letters imported into DOCUSKY from MARKUS along with metadata on each letter. The textual database in DOCUSKY allows for the simultaneous use of user-supplied metadata (boxed here), tags (on the left; comments if included will show on the right), and natural keyword search for exploring the corpus. Personal name tags link to CBDB.
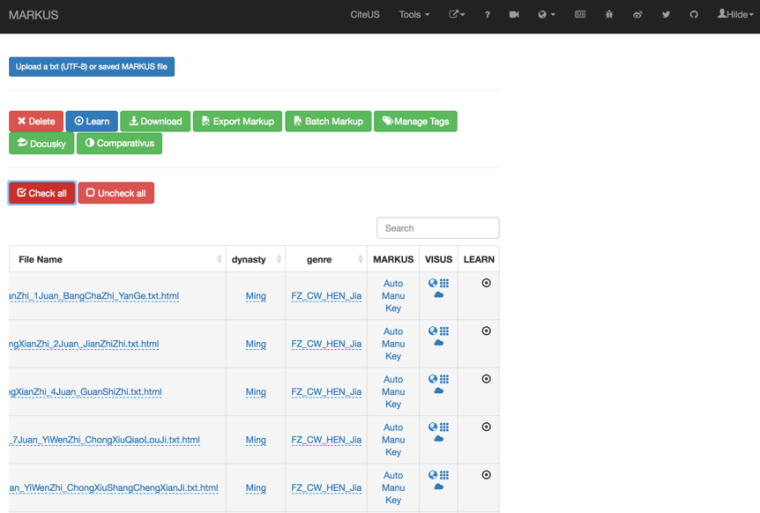
Figure 4B. MARKUS file management view. After setting up a free and private account, users can access saved files and select files for a range of operations.
MARKUS is thus designed and continues to be developed to model existing research flows, allowing for flexible switching between markup, reading, exploration, analysis, and annotation. I have learned much in the process of participating in this endeavor in a variety of ways. Participating in the design and implementation of research infrastructure increases one’s awareness of the strengths and weaknesses of digital media and methods and allows one to be critically and constructively engaged in their development and to contribute towards their improvement and alignment with humanities priorities. This experience also allowed me to see the importance of collaboration within academia and across sectors. Most of the added functionality and scheduled features come from the input and contributions from humanities researchers and students (such as relational markup which will allow for different types of relationships to be established between entities, text comparison in COMPARATIVUS (Mees Gelein, Hilde De Weerdt, and Brent Ho) which allows for the exploration, selection, and export of text overlap between texts (Figure 5), or machine learning (Miao Shengfa and Brent Ho) to improve the accuracy and recall of automated markup).
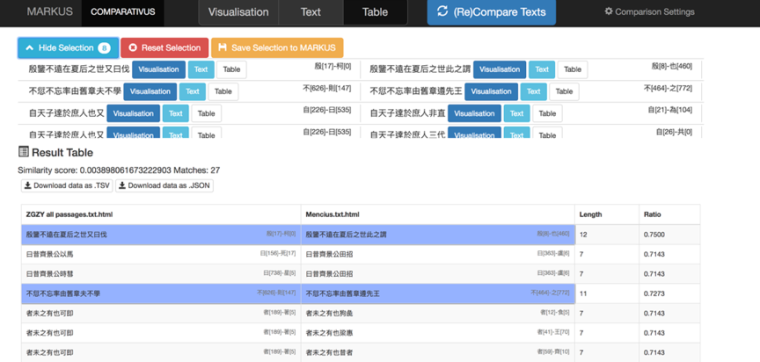
Figure 5. Comparison of text overlap between Zhenguan zhengyao and Mencius in COMPARATIVUS, showing selection from the table view for export to CSV and/or to the associated MARKUS files if the files were loaded into COMPARATIVUS from the MARKUS file management view (Figure 4B).
This kind of collaborative endeavor is not new in historical scholarship. In the first part of the twentieth century our predecessors in Tang and Song history compiled indexes, concordances, dictionaries, and other reference tools to facilitate their own work and that of others. In many ways developing digital tools is an extension and enrichment of these kinds of collaborative ventures, which have contributed significantly to the development of the field of Chinese history. We will need more of this if we want to ensure that the resources for which our institutions and we pay will be used well in the future. At the same time this engagement will present new challenges. Finding institutional solutions to keep services alive is but one of the many challenges that digital historians face. Developing curricula to ensure adequate training in humanities-specific computational methods, theoretical and critical approaches to digital media, as well as the critical assessment of both traditional and digital philological tools are also urgent tasks.
MICROSCALE TEXT ANNOTATION
In my experience so far, the investment of time in generalizing digital methods developed for one project pays off. It pays off when it gets taken up by others who work with it to make new findings in their own fields. It also pays off for the individual researcher. Following the completion of my work on notebooks, I started working on two microscale projects: a study of Yang Wanli and his correspondence and a translation and study of Zhenguan zhengyao. The former is part of comparative historical project aimed at juxtaposing the modes and effect of political participation by literati and clerics in Song China and medieval Europe mainly through a close reading of their correspondence. The latter started out as a collaborative effort to render this core text in Chinese political thought in English as part of the expanded Cambridge University Press series Texts in the History of Political Thought. The work we had already done on MARKUS has contributed in different ways to facilitating this work; the experience that tools can be modified to make them more suitable to the questions and needs at hand also inspired us to undertake further development to enable the kinds of microscale analysis that many historians are engaged in.
In order to gain a better grip on Yang Wanli’s letter collection, which includes nearly 500 pieces, I decided to combine more traditional note taking techniques with a multi-perspectival digital exploration of the text. I tagged all named entities in the letter titles and letters, but I also I added time and place of writing as well as the author’s position at the time to each letter title when this was known from modern editions and chronological biographies (nianpu). In addition to this metadata I also included the key themes addressed in the letter. In MARKUS I can convert this kind of annotation into a faceted overview of the collection and navigate through it by time, place, addressee, theme, places or people discussed in the letter, post of addressee or of the author, in maps, timelines, network views, tables, tag and word clouds etc. I can combine my data with those imported from CBDB to either gain total overviews, or to zero in on periods, themes, and letters that merit attention (Figures 4, 6-8—based on 250 letters). Some of this could have been done by compiling an excel sheet, but the combination of metadata, full text, and the broad range of visualization options make working this way far more flexible, and, time and again, has allowed me to modify impressions gained by unaided close reading. As partially evident in the figures some overall conclusions can be drawn about this corpus on this basis (the prominence of state councilors as addressees and the dominance of letters written from Jizhou to the capital, for example), but as this work is still ongoing it is here mainly adduced to demonstrate the methodological and philological strengths of this approach.
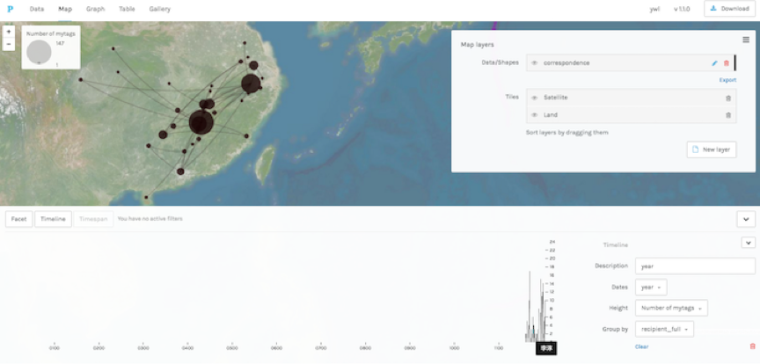
Figure 6: Map and timeline overview in Palladio of the correspondence of Yang Wanli (sample of 250 letters) tagged in and exported from VISUS interface in MARKUS (Figure 4B).
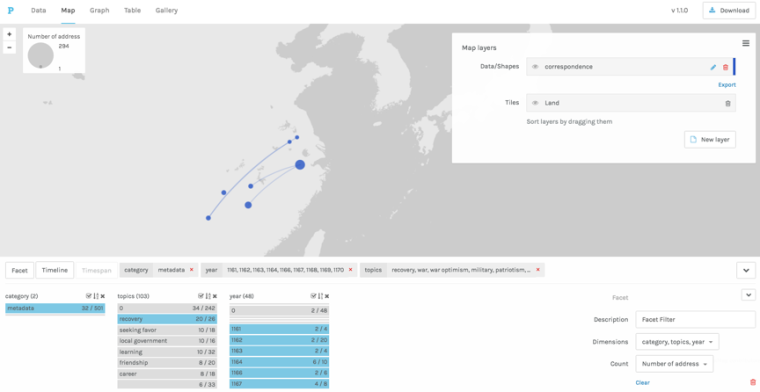
Figure 7: Faceted browsing in the map view of Palladio of the correspondence of Yang Wanli (sample of 250 letters) tagged in and exported from VISUS (Figure 4B).
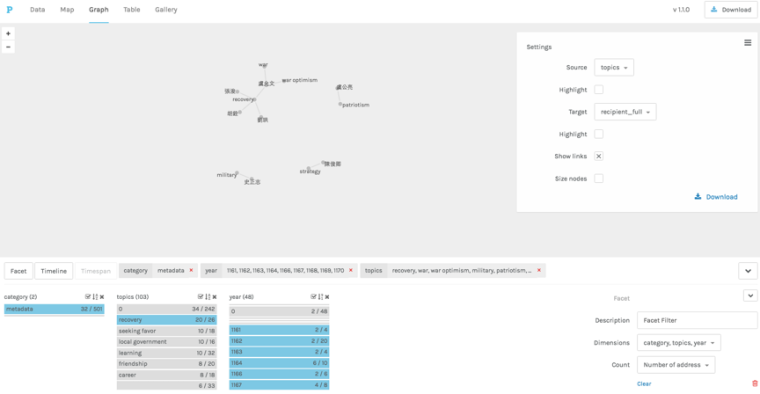
Figure 8: Faceted browsing in the network view of Palladio of the correspondence of Yang Wanli (sample of 250 letters) tagged in and exported from VISUS (Figure 4B).
In our translation of Zhenguan zhengyao we are employing tagging for yet different, mainly editorial, purposes. We tagged the entire texts to generate the kinds of standardization tools that joint translations require: lists of official titles and indexes of place names, personal names, and book titles. Readers will also be able to use this file, however, to quickly retrieve passages based on these criteria and others they might want to add (such as text reuse tags generated through COMPARATIVUS as shown in Figure 5). We are also developing a flexible digital edition that will allow readers to read the text in more ways than the standard layout: passages can be aligned according to chronological sequence for instance, or rearranged according to their sequence in different editions.
There are plenty of unintended consequences and surprise finds in digital research and working digitally may spiral into further investments in shaping the digital philological methods of the future. After having manually tagged the names of informants in Wang Mingqing’s Huizhu lu, for example, I continued to tag all personal names in it in order to see what this would reveal about who was mentioned most frequently, who was mentioned by whom, who was mentioned with what other historical figures, etc. Using different ways of measuring the centrality of those mentioned in the text, I could corroborate some of what I had suspected (the centrality of Cai Jing, for example), confirm less obvious tendencies in the text (the centrality of Zeng Bu and Gaozong), and also uncover how sentiments attached to central figures can be explored (not only through terminology but also through clustering and the dependencies of some actors on others). Such finds can lead to new algorithms for detecting bias in larger corpora of texts and help historians make decisions about what texts to include in their analyses and how to place them in their larger intellectual and political context.
IN CONCLUSION
I hope to have suggested in my comments above that digital methods are suitable for a wide spectrum of historical research projects, ranging from the close reading of particular texts and the exploration and analysis of larger corpora to the extraction and mapping of data from tens of thousands of documents. Digital analyses need not lead back to quantitative history exclusively; we can now accomplish different kinds of historical writing with them. We can help uncover the structure and knowledge embedded in historical texts and objects with digital methods--as in the case of one of my first GIS projects which was aimed at reconstructing the reading instructions that accompanied one of the first printed maps of the Chinese territories. We can experiment with social scientific history using network analysis, sampling, and probabilistic methods to test prior conclusions, raise new questions, highlight lacunae in prior scholarship, and propose new explanations. And we can continue to develop and work with philological tools that build on and strengthen those that have laid the foundation of historical scholarship in early modern and modern times.
NOTE
For this piece I was invited to contribute my thoughts on historical practice and computing based on my own work. The following explore the thoughts articulated here further:
BLOGPOSTS:
Collaborative Innovation and the Chinese (Digital) Humanities. University of Nottingham China Policy Institute Blog, June 9, 2016, https://blogs.nottingham.ac.uk/chinapolicyinstitute/2016/06/09/collaborative-innovation-and-the-chinese-digital-humanities/
Isn't the Siku quanshu enough? Reflections on the impact of new digital tools for classical Chinese. Communication and Empire: Chinese Empires in Comparative Perspective, Feb. 20, 2014, http://chinese-empires.eu/blog/isnt-the-siku-quanshu-enough-reflections-on-the-impact-of-new-digital-tools-for-classical-chinese/
Digital Interpretations. Communication and Empire: Chinese Empires in Comparative Perspective, Feb. 5, 2014, http://chinese-empires.eu/blog/digital-interpretations/
INTERACTIVE READING PLATFORM
Information, Territory, and Networks: The Crisis and Maintenance of Empire in Song China--Accompanying data and visualization site. 2015. http://chinese-empires.eu/reference/information-territory-and-networks/
PODCAST
“Hilde De Weerdt on MARKUS.” 7/31/2016. DH East Asia Podcast. http://www.dheastasia.org/2016/07/31/podcast-3-hilde-de-weerdt-on-markus/
SOFTWARE
MARKUS: A markup, reading, and visualization platform for classical Chinese texts (with Brent Ho) 2014- http://dh.chinese-empires.eu/beta/
MARKUS instructional videos. https://dh.chinese-empires.eu/markus/beta/video.html (English) https://dh.chinese-empires.eu/markus/beta/video_zhtw.html (traditional Chinese) https://dh.chinese-empires.eu/markus/beta/video_zhcn.html (simplified Chinese) 2014-
COMPARATIVUS: A text comparison platform (with Mees Gelein, Brent Ho)
http://dh.chinese-empires.eu/comparativus/
Tu Hsieh-Chang, Hsiang Jieh et al. Docusky. http://docusky.digital.ntu.edu.tw/ Instruction manual (inc. basic MARKUS instructions):
https://docusky.digital.ntu.edu.tw/DocuSky/ds-11.instructions.html
VIDEOS
Digital Perspectives on Middle-Period Political History. 4/5/2016. University of Michigan, Ann Arbor, Lieberthal-Rogel Center for Chinese Studies. https://youtu.be/2oxHTEFEa38 (different versions of this talk: Gothenburg http://media.hum.gu.se/filedb/index.php?cdir=TmpVNU1qZz0%3D&c_hash=62c1644730fcf46086164dc08fdcf5e8 and http://media.hum.gu.se/filedb/?cdir=TmpVNU1qYz0%3D&c_hash=41c9fba5f4490c7c0501ac047752a02b and Stanford https://vimeo.com/168242706 )
Humanities Tools for Library Resources. 4/4/2016. University of Michigan, Ann Arbor, University Library. http://leccap.engin.umich.edu/leccap/viewer/r/azO7QY
文本標記與歷史研究 (Textual Markup and Historical Research). 4/29/2015. Academia Sinica, The Institute of History and Philology, Taipei https://www.youtube.com/watch?v=NltG3EjC9_A
宋代新資訊結構的形成 (The Development of a New Information Regime in Twelfth-Century Song China) 4/27/2015. National Taiwan University, Chinese Department, Taipei https://www.youtube.com/watch?v=1Xd_mJ9eJHk
-
C clareqiaoposted in Research blogs • read more
[This blog comes in two parts. Part 2 is posted under the title "The Uses of Digital Philology in Tang-Song History - Part 2".]
Hilde De Weerdt (1/14/2017)
Prepublication version for Tang Song lishi pinglun special issue “Data and Digital Tools” for which I was asked to reflect back on my engagement with digital research in the field of Tang-Song history; updated with select features (DOCUSKY and COMPARATIVUS) 2018.
In the last five years Chinese historians have, like their counterparts working on other parts of the world, woken up to the fact that digital history need not be a reduction of texts to quantitative data and the aggregation thereof. They have come to see that with digital philology historians can supplement and enrich the repertoire of analytical perspectives and hermeneutic strategies that can be brought to the texts and material objects they study. In the brief communication that follows I will give an overview of some of the ways in which I have engaged with digital approaches to historical texts from the Tang and Song dynasties and discuss how I integrated these into my longer-term research projects on Tang and Song political and intellectual history.
FROM STAND-ALONE DATABASES TO LINKING DATA
Most historians have been working digitally for some ten to twenty years. Beyond the more obvious word-processing tasks and simple searches that we perform on a regular basis, many have also been creating tables, spreadsheets, and databases in the standard office software packages that have gradually come to supplement, if not fully replace, the notepads and card files of the past. The beginning of my exploration into the new terrain of digital humanities started off in this way. In 2007 I examined the data and the structure of the China Biographical Database [hereafter CBDB] to see what they might have to offer to someone interested in researching correspondence networks in twelfth-century Southern Song China. In the rudimentary report I presented at the “Prosopography of Middle Period China: Using The Chinese Biographical Database” Workshop that year I concluded that CBDB was then unsuitable for research on correspondence networks due to a lack of relevant data. I also concluded that the model could and should be extended both by the ingestion of existing reference works and by more fine-grained smaller-scale research projects. In the process of investigating the CBDB (and reading through a database development manual) I had, moreover, become aware of the benefits that linking texts and notes I was gathering in the process of my own research to the CBDB might have.
I made a first step in this direction while investigating the social and cultural history of note taking and the printing of notebooks in Song China. As part of my larger investigation into the reception history of texts relating to current affairs and dynastic history such as court gazettes, archival compilations, maps, and policy documents, I set out to compile a table of all printed editions of notebooks (biji) published during the Song Dynasty. I transformed the table into a spreadsheet listing author name, original title, standard title, original date of compilation, date of printed edition, printer name, patron name (if any), place of printing, current holding location (if the edition was still extant), and the source(s) attesting the existence of the printed edition. I was able to go much further in my analysis of the social and geographical backgrounds and careers of many of the authors by connecting my data to the biographical details contained about them in CBDB, which was being rapidly populated with prominent Song biographical reference sources at the time. I could also map the locations in which biji were printed by linking the place names mentioned in prefaces and catalogs to the coordinates listed in the historical geographical datasets provided by Lex Berman and others in CHGIS. I argued on the basis of the resulting data that we see in the social history of Song biji publishing not a shift in authorship from high court to local office-holders and to those without official rank (as Zhang Hui and others have maintained) but rather a broadening of authorship with high court office-holders continuing to play an important, but no longer dominant, role in printed texts and with court politics continuing as a central concern in the genre (see also, De Weerdt, Information, Territory and Networks, ch. 6).
I later extended this methodology of linking the data I gathered myself to existing databases that could enrich them to the digital text of the notebooks I selected to read in full. It struck me in reading Wang Mingqing’s series of notebooks titled Huizhu lu that the best way to analyze the information network embedded in the text would be to create a database in the text itself. Wang Mingqing frequently mentions in his notebooks the person(s) with whom he had conversations, his source texts or the authors whose books he read, the collectors he visited etc. I annotated a digital edition of the text, tagging entry per entry who served as an informant on what kinds of topics and which texts he commented upon. By adding the CBDB id for each person thus referred to in the tags inserted in the digital text and then connecting the data from my text files to CBDB, I was able to import from the latter database the dates, native place, and career information for hundreds of individuals mentioned in the text. This would have been tedious and practically inconceivable without digital methods. Even though I still added or corrected information on dozens of individuals (curating data always remains a necessity), the ready availability of such information from authoritative (if not infallible) reference materials such as Chang Bide’s 昌彼得 Songren zhuanji ziliao suoyin 宋人傳記資料索引 or Li Zhiliang’s 李之亮 Songdai junshou tongkao 宋代郡守通考 meant that reconstructing the temporal, social, and geographical dimensions of Wang Mingqing’s information network as reflected in his notebooks became a feasible experiment.
I included this work in Part II of my latest book Information, Territory, and Networks: The Crisis and Maintenance of Empire in Song China. In this work I argue that a structural transformation took place in the production and dissemination of information about the Chinese polity. Genres such as maps showing the Chinese territories, archival compilations, court gazetttes, and military geographies, which had been authored mainly by court officials for consumption by the same group, were by the twelfth century authored, read, and commented upon by cultural elites living across the Song Empire. I trace these changes in political communication between court and literati at the level of institutional change, legal history, and cultural production. On the basis of systematic analyses of notebooks and other genres recording literati reading practices, I further argue that the surge in literati textual production exhibited two important features that led to a tendency towards the formation and maintenance of large imperial states in Chinese history from this point onwards. First, literati tended to articulate an imperial mission, a commitment to an idealized Chinese commonwealth, in secondary discourse about the polity. Second, the scope of the networks through which texts were exchanged tended to be broad, diverse, and geographically crossregional. It was my exploration of digital methodologies that made the latter findings and the novel examination of the reception history of state documents and the communication networks of literati possible.
I expanded the initial experiment with a group of graduate students (Lik Hang Tsui, Chen Yunju, Li Yun-Chung, and You Zixi) into a further examination of a broader selection of notebooks. Our original datasets are available for download from the site accompanying the book. With the help of Brent Hou Ieong Ho I also transformed the texts and data into an online platform that allows for the interactive visualization of the information networks embedded in the encoded notebook texts. Readers can test arguments made in Information, Territory and Networks and perform other analyses of the texts and data. Readers can:
• create heat and cluster maps of the places where informants hailed from or served in
• compare the temporal distribution of authors in different notebooks
• analyze the social backgrounds of informants by examining their office-holding record or absence thereof
• check on the frequency of citation of different kinds of informants or individuals across notebooks
• link back to the passages in which informants occur
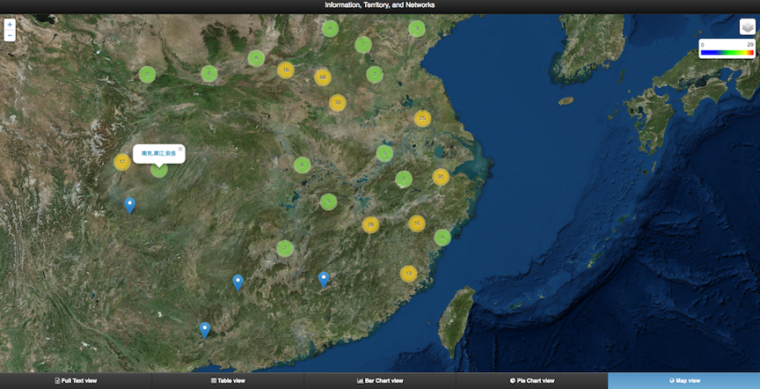
Figure 1: Interactive platform for selected Song notebooks, showing native place information of informants and, at the bottom, the buttons for other view options including full text, table view, and chart views.
By examining the social relationships thus commemorated in notebooks I gained new insight into the genre and its development across the Song period. This kind of reading in context, alongside other forms of digital reading such as the corpus linguistic analysis of different editions of the text in chapter 8, transformed my earlier close readings of the texts and informed my interpretation. It allowed me, as a modern reader for whom contextualization always remains a challenge, to develop new insights into the ways in which individuals such as Wang Mingqing articulated distinctive positions on shared literati concerns such as Song-Jin relations in his notebooks.
MACROSCALE TEXT EXTRACTION
My first exploration of digital methods took place at the micro- and meso-scale of source analysis. I was either working with individual texts (one set of notebooks compiled by one author) or corpora of selected texts from a small number of authors from the same period. With digital methods we should be able to do more. Digital reading holds in my view a unique promise to allow the researcher to zoom in and out. We are used to doing this now with images of art objects and material artefacts, zooming not only into the regions and details of the individual object but also zooming out to the larger collections and subcollections in which it has come to classified (for a nice example, see Florian Kräutli’s Timeline suite for digital curation). The same holds for texts. Digital curation allows us to scale up and down, but we have yet to examine how this can be best done. For historians the importance of scaling is readily evident when we think of developments that involve an entire class of people, a vast area, or centuries of time. I will provide two examples of ongoing projects to explain how digital approaches can allow us to explore the macroscale in our work, one in the area of political history, the other in the area of urban history and the history of technology.
Political and intellectual historians of the Song period have long debated the factional struggles that involved large numbers of scholar-officials between the eleventh and thirteenth centuries. The majority of the large number of studies on key moments in this history have focused either on the representation of events in court chronicles or on individual cases of well-known, and in some cases such as Huang Kuanchong’s work on Sun Yingshi, more peripheral, actors. Within this framework it is difficult to develop a sense of how alliances were formed among larger collectivities. Networking was intertwined with the career of literati at various stages. It was essential when preparing and sitting examinations, seeking appointment and re-appointment, or when obtaining patronage for other types of employment. Networking involved literati in political coalitions. If it is the case that networking of this kind was necessary for careers and therefore pervasive, it follows that historians need to understand how factional politics worked not only at the top but also in the provinces. I believe that the larger question of how far factional politics filtered through to the provinces can be better answered by devising methods to explore the entirety of the existing record. With a group of postdoctoral fellows and doctoral students I have begun to analyze how the co-occurrence of the names of the men who appeared on factional lists can be used to explore such questions. Through a comparison of three key moments in factional struggle in the twelfth century we also aim to address the question of how factional alliances were transformed in the context of the broader social and cultural changes of the Song period.
In a preliminary experiment we ran the names (including alternate names) of all those mentioned on the Yuanyou list (1100s), those persecuted by Councilor Qin Gui 秦檜 (1090-1155) (1140s), and those on the Qingyuan roster (1190s) through three collections of texts. Each collection consisted of all prose texts gathered in the collected writings of authors who were active during the time the lists were compiled. (In Chinese Studies we are fortunate to have access to large corpora of digital texts that make analysis at this scale feasible.) We included the collected writings of all Song authors whose CBDB index year (normally 60 years of year of death) fell within a sixty-year range (-30 to +30) of the date established as the publication date of the list of names: 1104, 1142, and 1196. The 1104 corpus consisted of 56,969 documents in 23,701,759 characters by 2,231 authors; the 1142 corpus 47,040 documents in 18,780,575 characters by 1,139 authors; the 1196 corpus 52,593 documents in 23,446,605 characters by 2,598 authors. Given the limitations of automated detection at this point the data needed to be curated carefully to eliminate occurrences that did not refer to the people in question.
What can we do with the curated datasets about the co-occurrence relationships amongst alleged faction members extracted from the collected prose writings of their contemporaries? From the datasets listing what documents discuss which faction members with what frequency we can see what authors, genres, and individual texts we may have ignored in earlier research and need to turn to in the future. Through network analyses of the co-occurrence relationships amongst faction members we examine whether the faction list network cohered in its entirety, what subgroups it was composed of, and what historical actors were central to the network and connected subgroups to each other. From here we return to the primary and secondary sources to further investigate the role of central actors and check on subgroups that appear to have been ignored to our knowledge. We also continue further analysis of the co-occurrence network by examining to what extent factors such as native place, family connections, and career experience may impact membership in the list in its entirety and in subgroups. Further down the line, we also aim to track how ties among faction members were represented over time by running the names against texts from later periods. This work is ongoing, but preliminary test runs of the clustering of names suggests that the structure of the presumed twelfth-century factions varied considerably, with the Yuanyou list forming a dense overall network and the Qingyuan list a more hierarchical structure, whereas no clear connections appear in the record for those persecuted by Qin Gui—demonstrating that historical network analysis can also be used to demonstrate the absence of relationships and network effects. We are also advancing current practice in historical network analysis and taking advantage of the largescale prosopographical and textual databases for Chinese history by developing sampling methods, comparing the networks resulting from co-occurrence and other types of relationship data to those of random samples of contemporaries. This work suggests, for example, that, on the basis of the extant record, Daoxue affiliates may have been an unusually close-knit group as running a sample of a hundred men whose backgrounds closely match those listed on the Qingyuan list through the same corpus of 52,593 documents does not yield comparable co-occurrence ties.
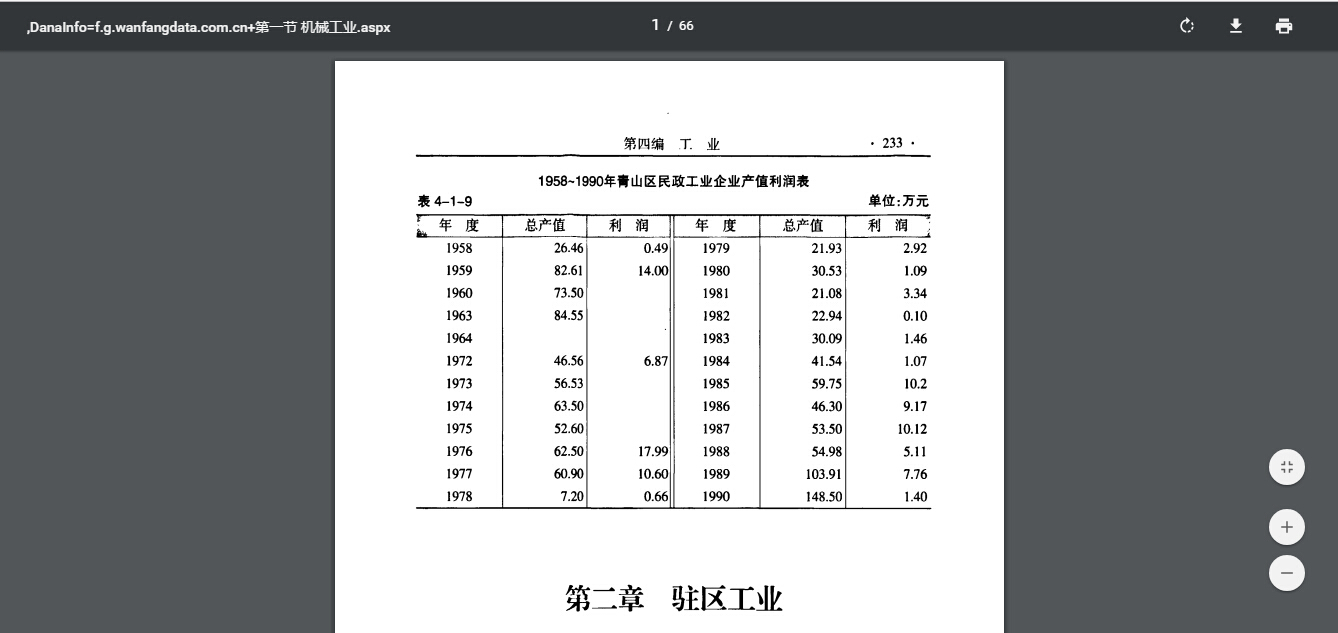
Data extraction of this kind can be helpful for a broad range of historical inquiry. With two other Ph.D. students, Xiong Huei-lan and Liu Jialong, I am currently also working on a longue-durée history of wall construction. On the basis of a set of regular expressions describing how information about the construction of walls is typically represented in wall and wall gate inscriptions (chengji, menji) and related records in local gazetteers and collected writings we are compiling a dataset covering the history of wall construction from the Song through the Qing periods. This will allow us to map, over time, the construction of walls, their maintenance, durability, materials, cost, labour force, design, size, location, and perceived functions. This kind of work should also benefit other historians, allowing, for example, urban and military historians interested in the comparative analysis of urban planning and military technology to work with nuanced datasets to draw larger conclusions about the relationship between city wall construction and the development of firepower.
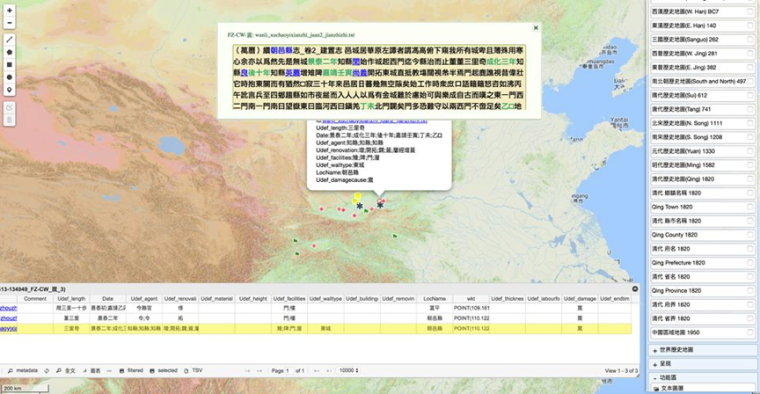
Figure 2. Pilot project on wall construction in Shaanxi, Guangdong, and Henan. Texts were marked up in batch for a wide variety of features in MARKUS, directly exported from MARKUS to DOCUSKY and DOCUGIS. Screenshot shows how the source text as well as the data extracted from it can be linked from the map features.
Such large-scale digital projects lend themselves to analysis at the macroscale and can also be designed to allow readers to zoom into the particulars of source texts, individual actors, particular places, or construction events. It may already be obvious that, in order to realize these goals, historians have to deal with new challenges. Much time will need to be invested in data curation; this is true for all digital projects—automated methods are never foolproof. Moreover, at the level of macroscale analyses, historians may have to adjust their expectations somewhat. Working digitally requires an adjustment in scholarly habits, a tolerance for experimentation and failure, for instance, and the willingness to deal with a certain measure of inaccuracy and messiness when working at elevated scales. Finally, this work cannot be undertaken by individuals. The collaboration of scholars with different types of expertise is required to develop humanities-specific digital methods and platforms that can lead to new insights.
[Please continue reading this blog at "The Uses of Digital Philology in Tang-Song History - Part 2".]
-
C clareqiaoposted in New Topic • read more
If you have used your custom tags to mark up a text, but then want to revise them, a video made by Wu Ruei-Ming 吳瑞明 as part of the Drugs across Asia project can be of reference value. As the video cannot be uploaded here, we have taken some screenshots to show how they did it. The video was recorded in the 正體中文 version of MARKUS.
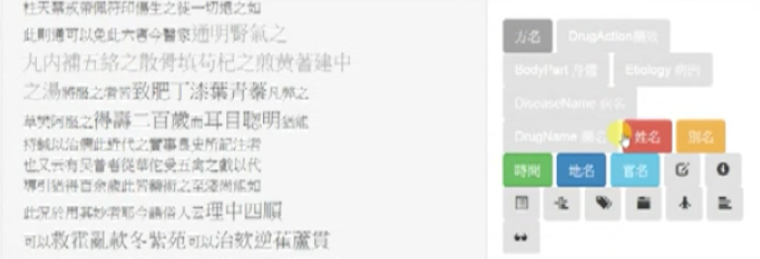
On the left side of the screenshot below is shown the text that has been marked up. Now, the user wants to change the five bilingual tags on the right into monolingual (Chinese) ones.
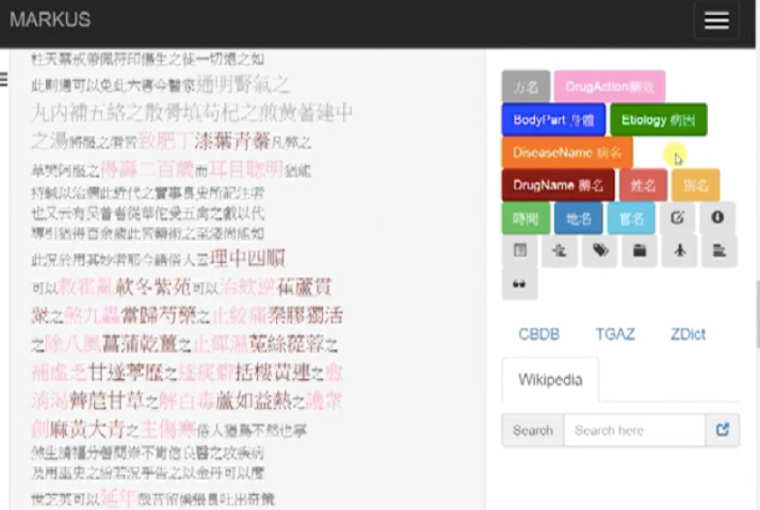
Basically, the logic behind the method shown in the video is to add five Chinese tags whose colors correspond to the ones they are meant to replace and then delete the bilingual ones. Here are the specific steps:
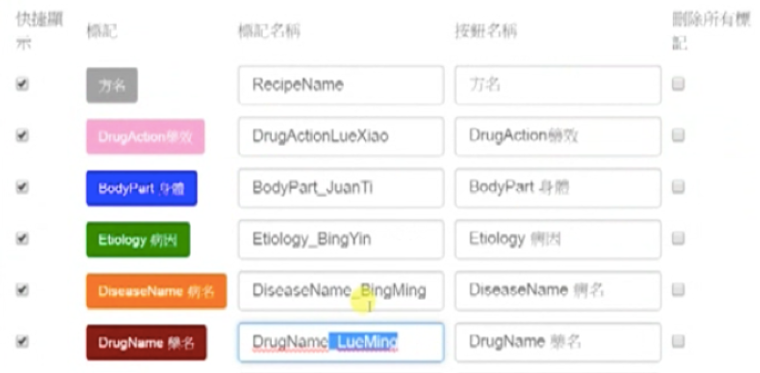
Click “管理標記”. In the window that pops up, change the tag names (標記名稱) of these five bilingual tags from following the earlier naming pattern of English translation + transliteration into just English. For instance, for the tag “DrugName 藥名”, delete “_LueMing”.
Having done this with all five, click “確定”. The five tags under revision now appear uncolored.
Click “管理標記” again, this time to change their button names (按鈕名稱) from being bilingual into just Chinese. For instance, for the tag “DrugAction藥效”, delete “DrugAction”.
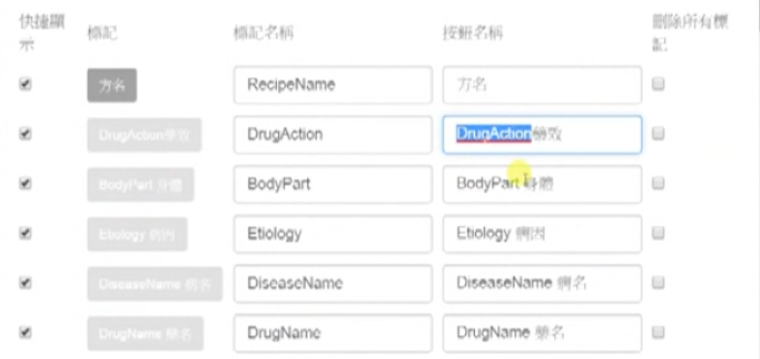
After having done this with all five, click “確定” and you’ll see in place of the five earlier bilingual tags, there now appear five Chinese ones.

Now let’s color them. Click “管理標記”. In the “新增標記” section of the popup window, for each of the five uncolored tags, copy its tag and button names into corresponding boxes and choose the same color as that for the tag it is going to replace. For example, choose crimson for the tag “藥名”. Then click “新增”.
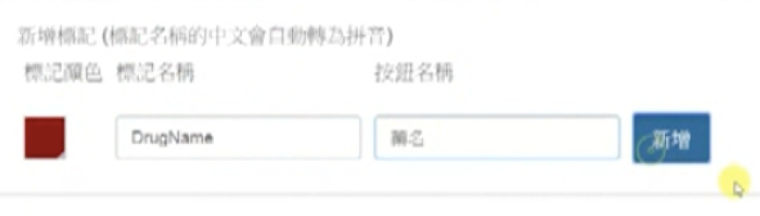
Now there appear two crimson tags.
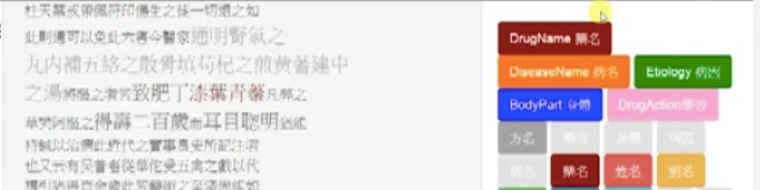
The next step is to delete the one you don’t want any more. Click “管理標記” again. In the window that pops up, delete the tag “DrugName 藥名”.

Click “確定” and you’ll see there is but one crimson tag “藥名”, which marks up all the named entities in the text that were previously marked up by the tag “DrugName 藥名”.
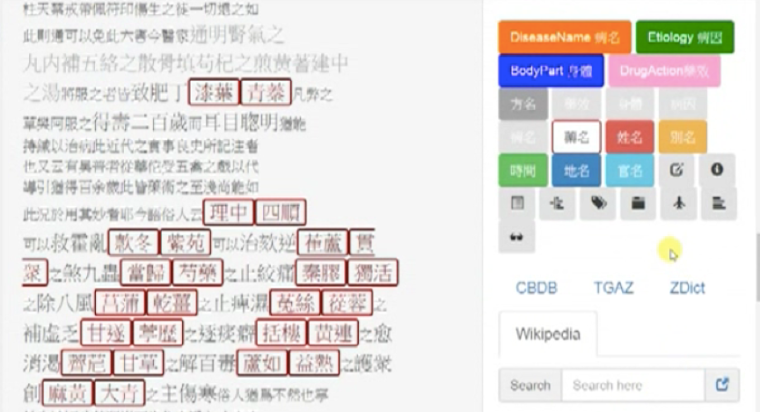
This completes the revision of this tag. Do the same for the other four tags, until you have revised them all.
Jiyan Qiao, PhD candidate, Leiden University
-
C clareqiaoposted in Research blogs • read more
In my study on the recorders of the Zhuzi yulei 朱子語類 (Conversations of Master Chu, Arranged Topically), I use MARKUS to identify personal names, place names, and official titles in the text.
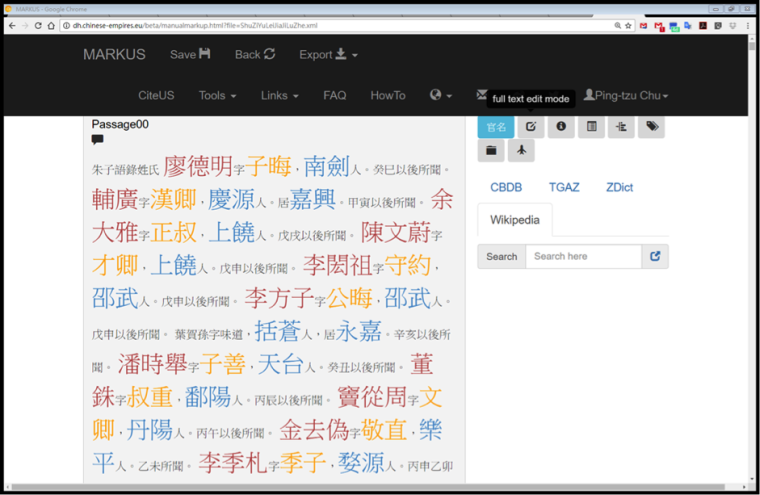
Then I extract the recorders’ main geographical addresses and the associated geographical coordinates by linking the person ids provided in MARKUS to the China Biographical Database (CBDB).
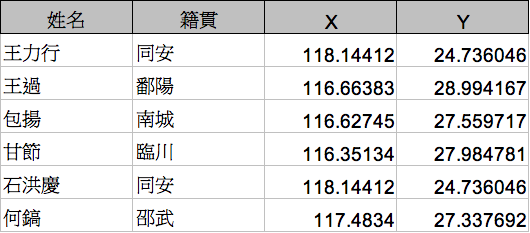
Putting these addresses on a map, we can observe the geographical distribution of the recorders.
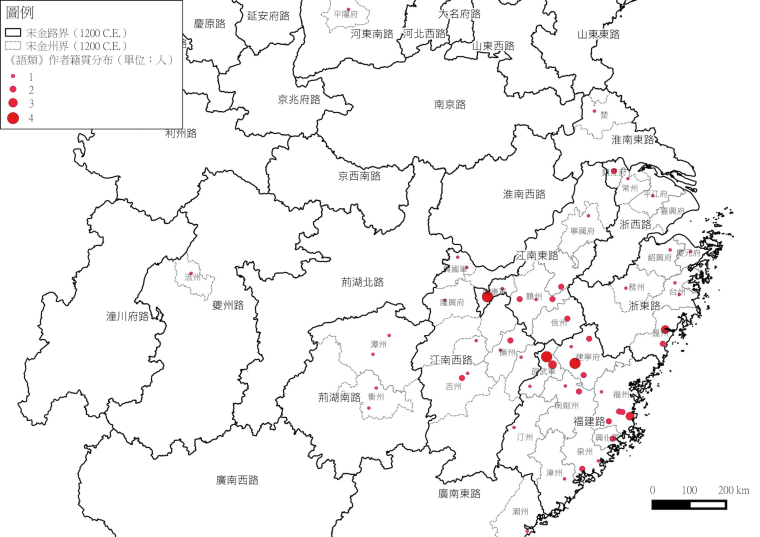
Figure 1 Geographical Distribution of the Recorders (by Mao Yuan-heng)
We can also get all Zhu Xi’s disciples from CBDB and do a comparison with the previous distribution map.
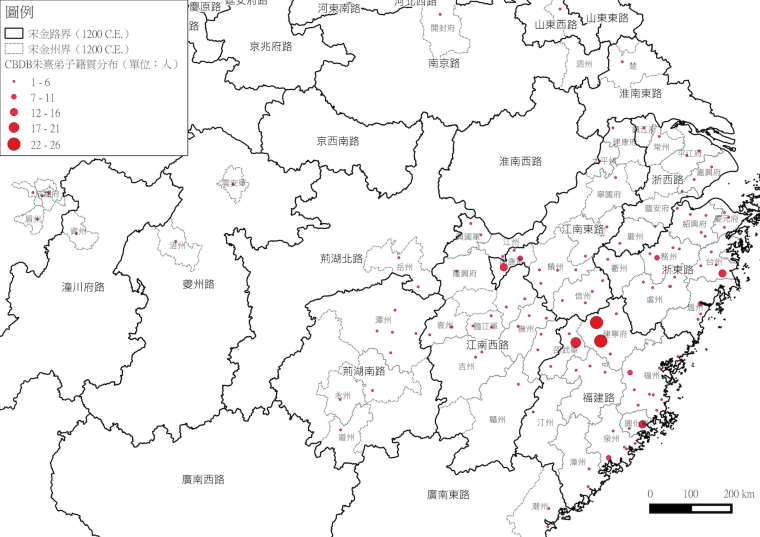
Figure 2 Geographical Distribution of Zhu Xi’s Disciples (by Mao Yuan-heng)
Some items in the Zhuzi yulei have more than one recorder -- probably a result of transcription or because multiple disciples heard the same conversation from Zhu Xi. We can use this as a criterion to group the recorders. If we suppose that those who recorded the same item share a tie and group them together, we can obtain the following social network graph.
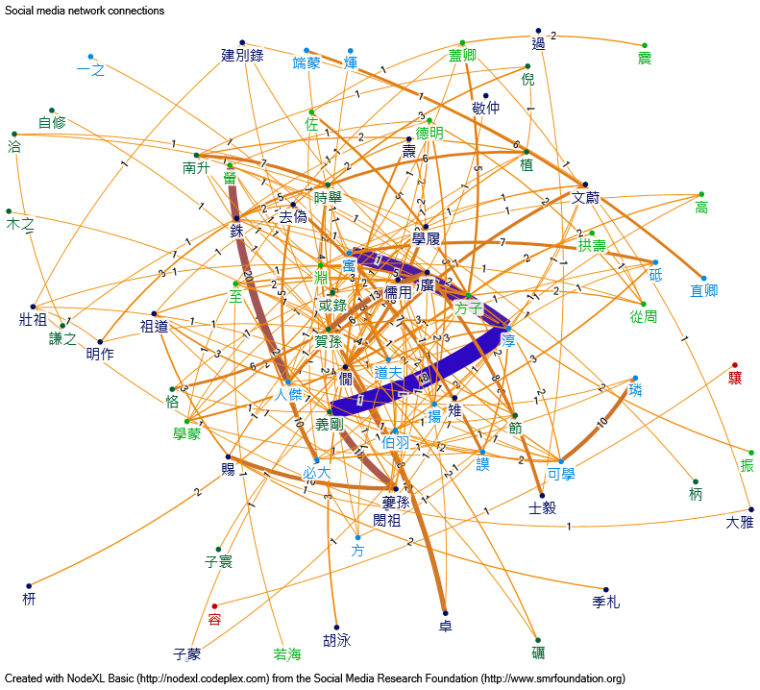
We can simplify the graph by only counting those who recorded the same item more than five times:
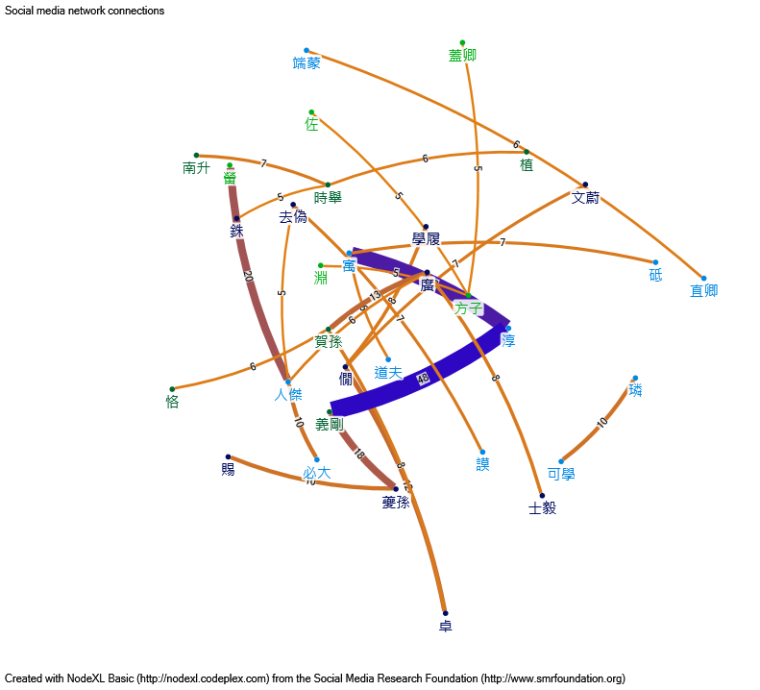
Thus in terms of recording, we can separate the recorders into groups based on those who recorded the same items.
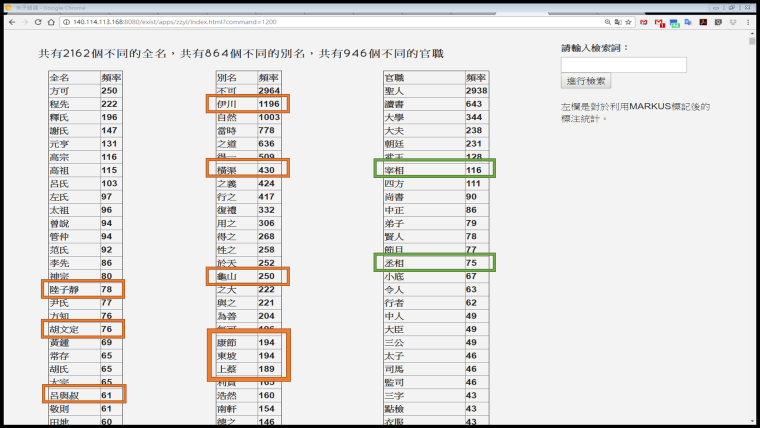
MARKUS also makes it easy and fast to get some specific information in a text, such as which place names, personal names or official titles are mentioned most frequently.
Chu Ping-tzu, Associate Professor, National Tsing Hua University
-
C clareqiaoposted in Research blogs • read more
The Song cultural elite were the first to develop an intense interest in collecting and studying ancient ritual bronze objects from the “Three Dynasties.” Several of the art catalogues and commentaries they compiled, some with illustrations, survive to this date. These antiquarian works provide information about the collectors, the items they collected, and their thoughts about antiquities. Moreover, these authors often referred to their predecessors from one or two generations before them and recorded their interactions with contemporary collectors and connoisseurs. The antiquarian works shed light on not only the Song elite’s study of antiquities but also their social relations with other collectors. With the aid of MARKUS and CBDB, my goal is to reconstruct the collecting circles for each of the antiquarian works, which will serve as a foundation for further analysis.
Here, I am using Jinshi lu 金石錄* by Zhao Mingcheng 趙明誠 (1081–1129) as an example to demonstrate how to extract information using MARKUS, how to process that information, and finally, the problems I encountered. What I show here is part of an ongoing experiment, and I welcome any comments and suggestions.
I. Extracting information
For each of the antiquarian works, I created Excel spreadsheets containing data of the collected items, collectors, and provenance by manually inputting information from earlier research. MARKUS might be useful in double-checking the missing data, particularly for the collectors mentioned in Jinshi lu, because Zhao Mingcheng used formulaic phrases when referring to the collectors: 藏…氏 and 藏…家. With “Keywords helper” in the Keyword function, the lists of collectors’ names were extracted instantaneously, as demonstrated in the following images.
Step 1: Keywords helper “藏…氏”
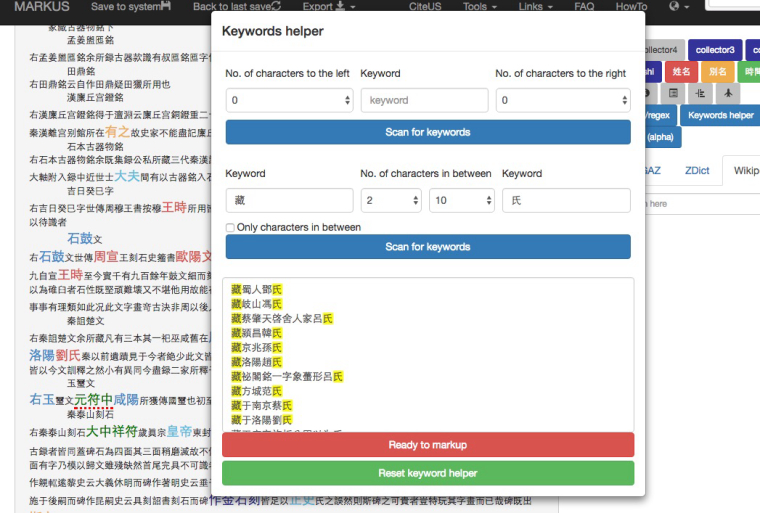
Step 2: Keywords helper “藏…家”
The results from Step 1 and 2 have high relevancy, as shown in the two previous screenshots.
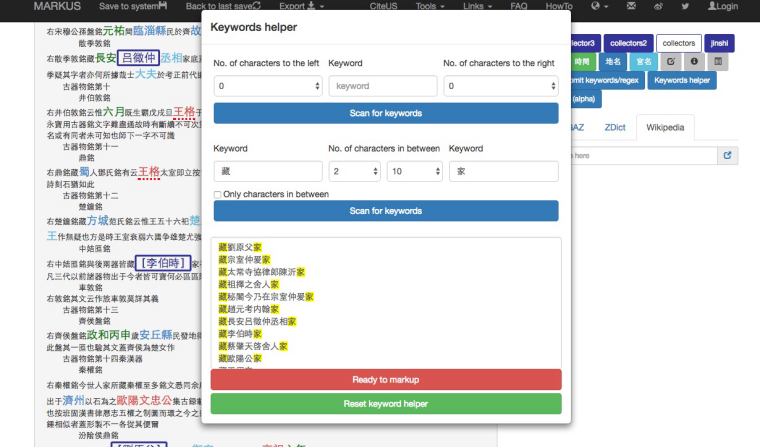
Step 3: Keywords helper “舊藏…家”
Zhao Mingcheng occasionally revealed the transmission of antiquities by using the term舊藏 to record the names of former collectors. Running the Keywords helper again with “舊藏…家” allowed me to identify the earlier collectors from the results of Steps 1 and 2.
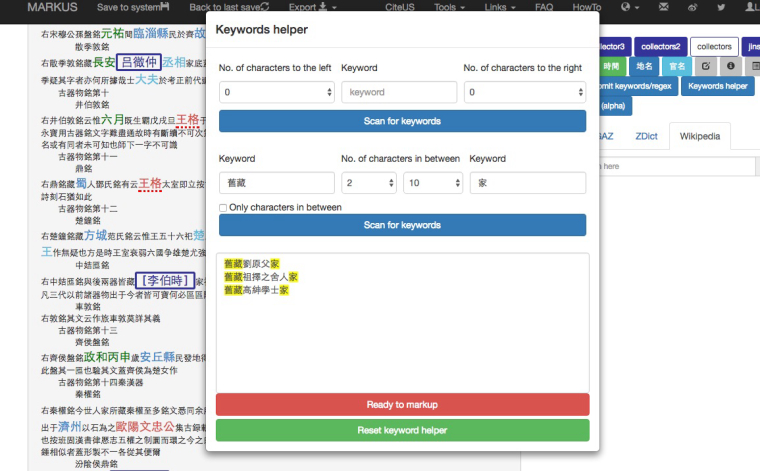
With Keywords helper, I could identify two missing collectors and thereby make my dataset more complete. In the case of Jinshi lu, although MARKUS was extremely effective in extracting collectors’ names, as previously demonstrated, when applying the keywords in the lists to mark up the text, a problem occurred. The application did not tag those terms that had automatic location markups, such as 方城范氏. MARKUS does not allow adding multiple tags to a term.
II. Processing the data
With the names of the collectors and connoisseurs found and extracted, the next step was to find their social relations in CBDB, import the association data to Gephi, and produce a social network graph of Zhao Mingcheng on the basis of the records in Jinshi lu, as shown in the following image. For greater legibility, the nodes with only 1 edge are purposely hidden. The bold, weighted lines are associations extracted from Jinshi lu, whereas the thin lines are social associations collected from CBDB.

Total: Nodes: 388; Edges: 443
After filtering out the nodes with only 1 edge: Nodes: 42 (10.82% Visible); Edges: 97 (21.9% Visible)
The juxtaposition of the association from Jinshi lu with other types of associations from CBDB allows us to explore and understand how the collectors related to one another in a larger social context. Some nodes are noticeable in the graph. Looking at the centrality values generated by Gephi is also helpful in identifying people of greater influence in the network. For instance, the betweenness centrality that quantifies the bridging capability of the nodes indicates Zhao Mingcheng, Chao Buzhi 晁補之, Liu Qi 劉跂, and Mi Fu 米芾 as the most pronounced communicators in the network. The reason for this is certainly worthy of further investigation.
The same approach was applied to four other antiquarian works of the Northern Song to generate network graphs for each work. Comparing these network graphs allows for an assessment of their relative scale and complexity, and taking the temporal dimension into consideration further affords a delineation of the long-term development of the collecting circles. Through the visualization of the social networks, I could observe how the circles related to one another and how the shape of the overall picture changed over time. As an historian and art historian working primarily with illustrated books and objects, I have not used the markup function of MARKUS extensively. But MARKUS is a versatile tool, with excellent Keyword functions for extracting information. MARKUS could also be a useful tool for students who want to read texts in classical Chinese. With various built-in dictionaries, one can read and understand the text more efficiently. In conclusion, what is presented here is a work-in-progress project. Comments and suggestions are welcome.
- The editions used in this study are:
- 趙明誠,《宋本金石錄》,北京:中華書局,1991。
- 趙明誠著,金文明校證,《金石錄校證》,桂林:廣西師範大學出版社,2005。
Ya-hwei Hsu, Assistant Professor, National Taiwan University
-
C clareqiaoposted in Research blogs • read more
I use MARKUS as part of a project to data-mine the Daoist and Buddhist Canons for materia medica terms. I use MARKUS in concert with a team in Taipei at Dharma Drum Institute for the Liberal Arts (DILA) to mark up texts. Having selected my textual set, I then go through each juan that we have identified as important. I first mark up the drug terms using Keyword Markup. This then draws my eye to the “action” of the text. I then analyse how drug knowledge is being recorded in that particular juan, and mark up a sample passage for important related terms. These can include alternate drug names, place names, illness terms, anatomical terms and many more. By marking up the sample, I establish what I expect the ontology of the drug knowledge in that text to be. I then forward the text to the team members at DILA, who clean up the rest of the automatic tags and follow my lead to completely mark up that juan. Once I have checked their work we forward it to National Taiwan University for uploading into Docusky. (For more details on the other parts of the project please see here).
MARKUS is an exceptional tool for its ease of use and speed. We have budgeted that we can mark up roughly 16 juan per month, with one person doing it in Taipei. This means that over the course of a year, we can complete roughly 200 juan. This figure is very useful for project design and planning. Knowing this, we can analyse a set of texts and know roughly how long (and how much) it will take to get them marked up. Currently we are marking up Six Dynasties texts for drug terms and recipes. We can use our results at the end of a year to calculate how much and how long it would take to mark up the entire Buddhist and Daoist canons.
Once the marked-up texts are loaded into Docusky, we will be able to analyse them based on all kinds of criteria. Where do different communities source their materia medica? What sects use which drugs, and at what time in history? Can we see recipes moving across the corpuses? We will be able to do large-scale analysis in ways that have never been attempted before. We can plot relationship graphs to see how close the drug repertoires are. The exciting part about this is that we are not just trying out how to research materia medica. This method could be applied for any repertoire of terms that one wants to learn about – pantheons of deities, for example, or ritual objects and bodily cultivation practices. Finally, historians doing close readings of texts will no longer have to assume that their text is representative. They can do statistical analyses to establish at scale how representative the texts they use for close-up analysis are. So I feel that this is the beginning of a new digital methodology.
There are a number of directions where MARKUS could fruitfully grow to become even more useful, but it will require investment of time and resources to make these possible. For example, it would be a great benefit if we could draw relationships between the terms in a given paragraph or text. This is important not just for prosopography, but for detailed recipe analysis as well, as drug interaction is a fundamental part of recipe design in Chinese medicine. Right now, I cannot tell if two drug names in the same paragraph are alternate names for the same substance, working in parallel in the recipe, or are antagonistic to each other. We need to refine the tool to make these relationships visible.
Furthermore, it’s very important to be able to mark up textual layers in an easy and user-friendly way. Historical Chinese texts are always layered – whether it be commentary, or different editions that have been combined, or if the text is a composite of different hands that have been spliced together. Marking these layers is critical not only for analysing the contents of the text, but dating them. It would be extremely useful even just to publish digital editions where the different layers have been marked up, allowing others to do digital analysis of the different layers.
MARKUS is very well-suited for individual researchers, allowing one a lot of privacy, and even the ability to store files in the cloud. Allowing people to do this in a collaborative way would make it much easier for teams to work together. At present, it takes a bit of training and sending of texts back and forth by email to bring collaborators onto “the same page.” It would be very helpful if everyone could see “same page” live onscreen at the same time. Eventually, as our research in Chinese materia medica matures, I would like to work with colleagues and use MARKUS to compare textual corpuses from different languages, such as Sanskrit, Tibetan, Mongol, and Persian. We could see how close the drug repertoires were across languages, and whether or how recipes travelled. However, MARKUS needs more development to be able to search in those languages, as well as integration with stemming tools or other kinds of features to track terms with spelling variants, or as they undergo grammatical transformation. This would enable MARKUS to have a much broader reach, opening up possibilities for translingual digital research, making it a very powerful tool for the history of science or material culture. Done in concert with teams of philological experts from multiple regions, we could use MARKUS and good translation rules to link primary sources from different languages, and do research on the global history of medicine in an entirely new way.
MARKUS has changed the way I read texts, how I collect and organise them, and how I construct arguments about them. However, I feel it has much more potential to fulfil, and not just in Chinese studies. I look forward to future changes as more and more people recognise the usefulness of this tool. Well done Brent and Hilde.
Michael Stanley-Baker, Postdoctoral Fellow, Max Planck Institute for the History of Science, Dept. III
Citation Ho, Hou Ieong Brent, and Hilde De Weerdt. MARKUS. Text Analysis and Reading Platform. 2014- http://dh.chinese-empires.eu/beta/ Funded by the European Research Council and the Digging into Data Challenge.
-
C clareqiaoposted in Research blogs • read more
I am currently writing an MA Thesis on the "Ten Friends of the North City Wall" (Beiguo Shi You 北郭十友). The image that we have of this group is mainly based on later sources and a few contemporary sources that describe a group of more or less ten young poets who were active during the late Yuan and early Ming in a district near the north walls of Suzhou. We know little of the inner dynamics of this network and how they as a group fit within a larger local network of Suzhou elites during the fourteenth century.
For my research I chose an approach based on the activities that these ten individuals performed together. Examining what activities people joined in, when and where, can provide context for understanding a social relationship. Together the “Ten Friends” composed around 5000 poems spread over 10 different collections. This huge amount of material raises for me the methodological problem how to identify the poems that help me find these activities. It is at this point that I found MARKUS especially useful. I used it to find the relevant joint activities that I would need for my research and it helped me to decide how to approach these activities.
First, I manually marked all the personal names and locations that appear in the titles of all the poems. I was then able to filter out exactly those poems in which multiple person names appeared together. These poems were often composed at an event that involved multiple individuals or they describe such an event having taken place. These poems also often told me who participated in an event, where, and when the activity was held. My results also allowed me to see at a glance which individuals participated in which activities, and which activities attracted the highest number of people. It also showed me at which places important social activities took place. I complemented my search with a key-word markup of all the other personal names and place names that appear in the poems that I had found. This helped me to find all the remaining poems that can be associated with a certain activity. This way using MARKUS I was able to find roughly twenty joint activities between the “Ten Friends” and others.
Then, I used my findings to create a network graph that links individuals (orange) to social activities (blue). The graph visualizes which gatherings, which individuals, and which places were most significant to this social network. Center activities were important in maintaining relationships between the “Ten Friends of the North City Wall” themselves, while periphery activities were less impactful on their internal network, but provided them with important opportunities to extend their circle outwards.
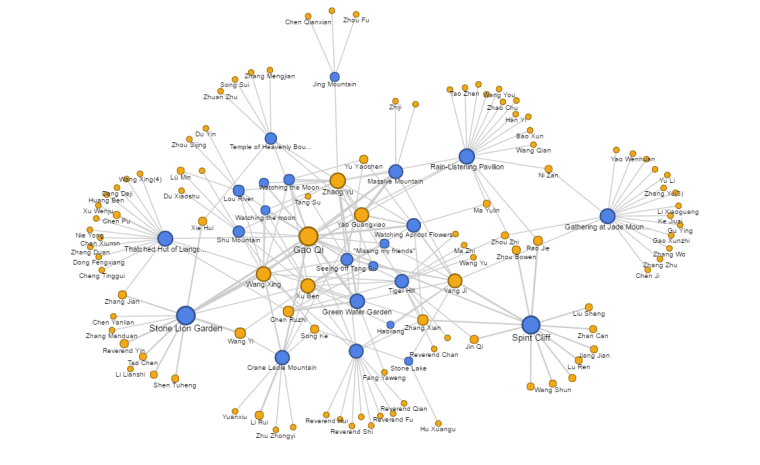
Social network graph of the “Ten Friends of the North City Wall” based on shared participation in activities (https://goo.gl/zP5HE4)
By locating the places on the map, and separating them into private (red) and public places (blue), I was able to quickly visualize the geographical spread of the activities. From the map I concluded that activities at privately owned places like rural residencies or exile destinations brought them far outside the North City Wall district in Suzhou where they lived together. Even while they were sent to various places, their involvement in activities at more public places like scenic sites, monasteries, and local estates, suggest a strong sense of local involvement.
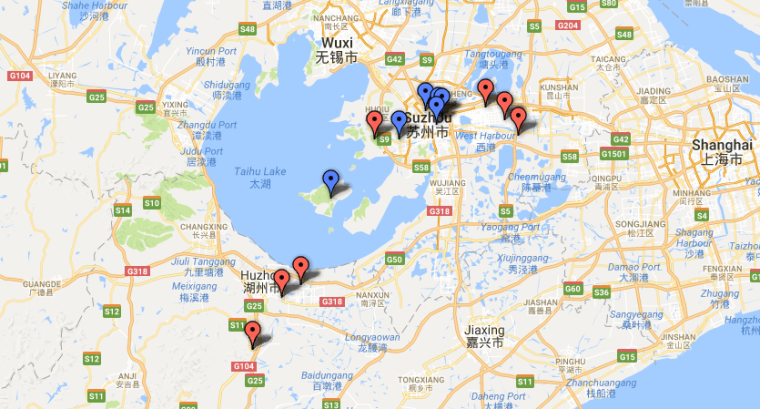
Geographical spread of the social network of the “Ten Friends of the North City Wall” (crop) (https://goo.gl/uVKlr8)
I used MARKUS in the early stages of my research. These early results already suggest that the North City Wall district only played a small part in the social network of the “Ten Friends of the North City Wall”. In all the 5000 poems I couldn’t find a single poem or prose piece that describes a concrete joint activity or experience that took place between ten or so individuals in this part of the city. MARKUS has shown me that to understand what bound this group together through the Yuan-Ming transition one has to look elsewhere. As the graph shows, one has to take into account a complex network of activities involving for each activity a different set of individuals. I have found relationships with a wide variety of individuals: with friends, politicians, famous artists, patrons, landowners, monks, etc. Each of these relationships have their separate activities, places, and memories. As can be seen from the map, the geographical center of this group is not fixed to a single place but shifts around, while it suggests a strong sense of locality.
Overall, the visualizations were a helpful tool throughout the whole research process and allowed me to determine what approach suited each activity best and how to relate each activity to other activities. MARKUS can be a useful tool that can bring us closer to understanding and visualizing the complexities of how social networks developed in time and space during the transitional period of the late Yuan and early Ming.
Levi Voorsmit, MA student, Leiden University
-
C clareqiaoposted in Research blogs • read more
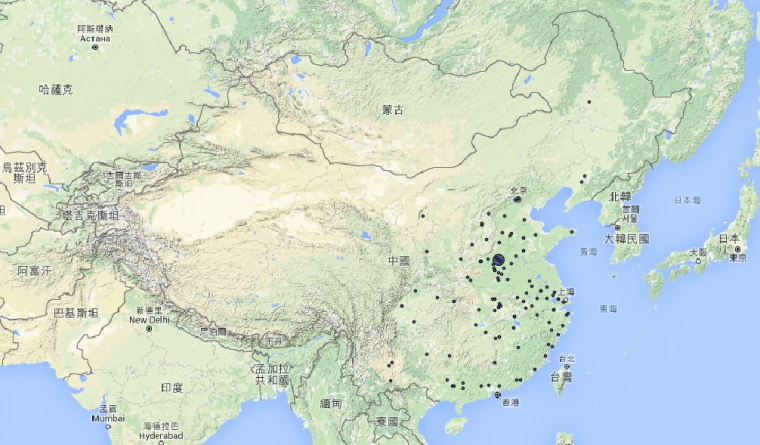
MARKUS is the reason I am pursuing my current research project. Inspired by Franco Moretti’s work, I had an idea about mapping the Chinese novel, but it seemed that it would be incredibly difficult to do it on a large scale using traditional methods. Then I learned about MARKUS, and its ability to identify place names in a digitized Chinese text. I tried it on my material, and found that with some manual correction, MARKUS gives me a good overview of all the places mentioned in a particular novel (or collection of fiction, like Baijia gongan 百家公案, below).
From that point I can decide what to map (using QGIS) and how to interpret it.
Map of places in the court case collection Longtu gongan 龙图公案, ca. 1644.
This is a big change from the way literature scholars usually look at places in the novel. We generally think in terms of types of settings or Bakhtin’s chronotopes, but relatively little attention has been paid to where those settings fall on a map. We don’t usually consider how frequently a place is mentioned in a particular novel, but doing so can be revealing. I intend to continue using MARKUS to investigate the use of space in hundreds of traditional Chinese novels, in order to bring back the vast number of novels that are usually overlooked. Once we articulate meaningful frameworks in which to interpret the results, digital tools like MARKUS have the potential to change the scale at which we do research.
Margaret Wan, Associate Professor, University of Utah
Professor Wan is currently working on a publication on this work. Stay tuned for an update.
-
C clareqiaoposted in Research blogs • read more
The China Biographical Database Project is a freely accessible relational database with biographical information about approximately 370,000 people, primarily from the 7th through 19th centuries. In our efforts to populate it with biographical data, we are using MARKUS for tagging historical Chinese texts and identifying information about historical figures that we can put into our database. From 2015 onwards, we have tagged persons’ names and government office titles in epitaphs (muzhiming 墓志銘) from Tang China (618-907 AD) as well as the Compilation of Song Regulations 宋會要輯稿, which is a collection of official documents from the 10th to the 13th centuries.
In our work on Tang epitaphs, we employ regular expressions to batch tag persons’ names and office titles mentioned in such epitaphs. After doing that we adjust the regular expressions to reduce errors due to irregularities in the text to a workable amount, we load the tagged texts onto MARKUS. Our helpers then use it to check whether the persons’ names and office titles are tagged accurately. Each of our helpers is assigned a number of epitaphs. The batch uploading function on MARKUS enables us to load all the epitaphs that we need to process for the project. After these checks are done, they can also batch download the data instead of downloading them one by one. After finishing these checks, we use a tailored Python program to extract all the persons’ names in an epitaph and create temporary IDs for those persons. Then our helpers will use MARKUS to create connections between those names and temporary IDs. (See figure 1) With this we obtain the names and office titles for those historical figures, which we will include in CBDB.
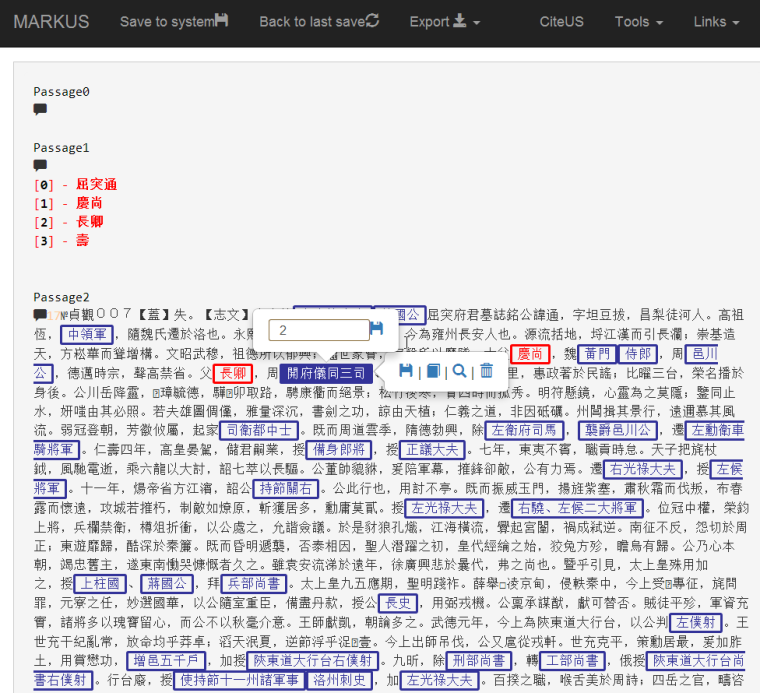
Figure 1, creating the relationships between office titles and person names
In our work on the Compilation of Song Regulations, we are implementing a similar solution. But there are two main differences. First, the texts from Compilation of Song Regulations that we use are XML files drawn from an online tagging analysis platform developed by the National Taiwan University's Compilation of Song Regulations System. The tags used by their system are quite different from the ones on MARKUS. Thus we developed a Python program to convert those tags to adhere to MARKUS standards. (See Figure 2) Secondly, since the biographical data that the Compilation of Song Regulations contains are much more numerous than in Tang epitaphs, we do not ask our helpers to link persons’ names to office titles manually. Instead we designed an artificial intelligence (AI) system to determine the probabilities of the relationships between persons’ names and office titles after we finish our training data. In this AI system, we have created some patterns to define the relationship between office titles and persons’ names within a paragraph in the Song Regulations text. For example, if there is an office title at the beginning of a paragraph, and if a list of persons’ names follow it, it probably means that the office titles should be assigned to each of the persons’ names behind it. We have already figured that this is the general pattern for many paragraphs in the text. By identifying this pattern, we associate historical persons with the office titles in such government records. This training data will be sent to the team developing MARKUS for further improving its machine learning function.
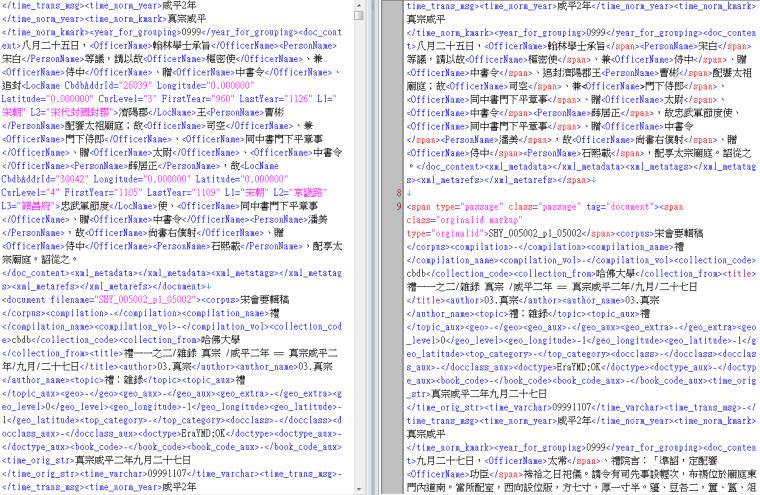
Figure 2, National Taiwan University's Compilation of Song Regulations System tag format
Hongsu Wang, Project Manager, The China Biographical Database, Harvard University, [email protected]
Lik Hang Tsui, Postdoctoral Fellow, The China Biographical Database, Harvard University, [email protected]