[This follows from “The Uses of Digital Philology in Tang-Song History – Part 1”.]
ON BECOMING A CO-DEVELOPER
It was the latter insight that motivated my involvement in designing MARKUS, a text analysis and reading platform for classical Chinese. When applying for a research grant to study political communication in Song history, I decided to include a fulltime postdoctoral position in computer science whose main responsibility would be to help develop methods for visualizing and analyzing communication networks on the basis of the annotation of private records such as notebooks and letters. As this project (2012-2017) draws to a close, I can now say that I am happy I made the decision to invest a substantial amount of time and resources into its digital research component. Historians usually outsource the creation of a website, database, or digital platform for their projects to internal or external parties. Such parties typically spend a limited (and difficult to schedule) amount of time on the project and tend to apply template solutions to the questions posed by their clients. By collaborating with a fulltime computer scientist with an interest in humanities scholarship I was able to begin to address some key problems in the larger environment of Chinese digital scholarship which I faced in my initial work on Huizhu lu.
First, as I discussed at greater length elsewhere, the leading commercial publishers of databases of pre-twentieth-century Chinese materials provided historians with large textual repositories since the early 1990s, but they have made little or no effort since to provide data discovery, visualization or text analysis tools that would allow us to better exploit the digital medium for research purposes. They continue to provide rather basic search functionality, outdated results management, limited and poor reference tools, and unacceptable limitations on the export of search results and the texts included. At a time when researchers should be able to collect and work with materials across vast and expanding textual archives, database design is still steering them to limit their search by genre, author, title, or, in the case of local gazetteers, by place. The packaging of text collections in separate databases has furthermore led to the proliferation of databases; the absence of interoperability has made it difficult for researchers to create collections of texts across different databases with which to do their work.
A second set of problems relates to the limitations imposed by software designed to give researchers better control over the texts they have gathered and the notes they have taken. When evaluating different methods to annotate notebooks and letters and research political communication, I first tried out commercial software designed for social scientists (qualitative analysis software) and then moved on to manually encoding files. The former included convenient tagging and visualization functionality, but commercial software suffered from a) a lack of interoperability with external databases (in our case CBDB or CHGIS); b) the absence of advanced export functionality which made exported results unreadable and unusable in other software; c) the use of propriety file formats which made sharing difficult and sustainability a concern; d) initially, but this is getting better, they were also ill suited for East Asian languages. Manually encoding files in standard formats such as TEI resolves these issues but proved to be somewhat inefficient (due to the repetitiveness of actions that could be automated) and visually unappealing to many students and researchers (due to the basic editor interface).
With Brent Hou Ieong Ho, whom I was fortunate to hire as a postdoctoral fellow in Chinese Digital Humanities, I set out to first generalize the methodology I had developed for encoding notebooks. By developing automated encoding for personal names, place names, official titles, and time references on the basis of CBDB, we were providing a service that offered better discovery and analysis functionality than standard databases and we were doing so in a way that was more efficient than manual encoding.
As we worked on this, we kept adding new functionality and designing the platform in ways that modeled the research flows of the historians and humanities scholars working with it. We added manual markup to allow not only for the correction and addition of default tags, but also to give researchers more freedom in defining tag types. We added dictionaries because the platform was not only used to tag and analyze tags but also to read through texts (figure 3). By adding language and domain-specific dictionaries, readers can simultaneously gain access to a wide range of standard reference works. We added a note feature, so that readers can translate, make notes, or leave to-dos for example for items that require further checking in print resources. We added keyword markup so that researchers can upload their own lists of terms to be tagged, and use advanced features such as regular expressions, KWIC, or a keyword generator (which produces keywords appropriate to the uploaded text based on a frequency analysis of the patterns in which one or more selected keywords occur) to analyze their texts. We added filtering options so that tags can be used to select passages that fit one or more criteria.
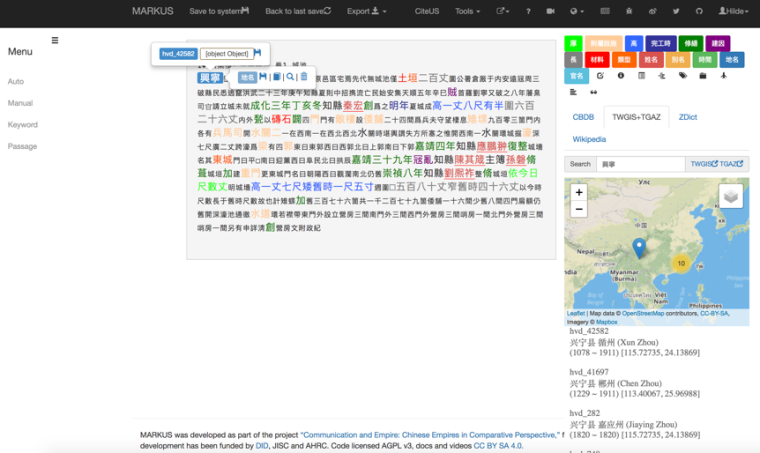
Figure 3: MARKUS platform showing an example of tagging and reference options as well as the option to add gazetteer ids to place names which can be used to map place names after exporting MARKUS files to DOCUSKY. Credit Xiong Huei-lan.
And, we continued to work on simplifying the many steps of extracting tagged passages, merging them with external databases, and then visualizing the combined data in separate packages. In the course of two years we developed MARKUS into a linked platform in which a large part of the annotation and visualization can be undertaken automatically. By linking files saved in MARKUS to Palladio (Humanities and Design, Stanford University) and PLATIN (Max Planck Institute for the History of Science) researchers can, via the VISUS interface, import biographical information linked to tagged names from CBDB and then explore it, alongside their own data, in maps, network diagrams, tables, timelines, pie charts, or tagclouds (Figures 6-8). More recently, we have added functionality to allow for the batch tagging (any number of tags to any number of files) and export of multiple files. Batches of MARKUS files can now be directly exported to DOCUSKY and DOCUGIS platforms (Hsiang Jieh and Tu Hsieh-chang et al., National Taiwan University) where they can be transformed into a textual database (XML) and where further text and spatial analysis of the text and tags can be undertaken (Figures 2 and 4). They can also export all data for more sophisticated analysis in more specialized spatial, network, or statistical packages. To improve access to texts and facilitate importing, we have also been linking to MARKUS from commonly used open access textual repositories such as Donald Sturgeon’s [Chinese Text Project](file:///Users/jqiao/Desktop/jobs/7 digital philology/ctext.org) and Christian Wittern’s Kanripo.
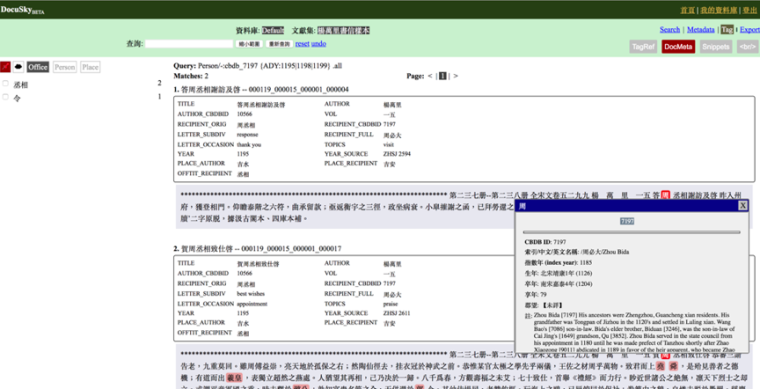
Figure 4A. Sample of Yang Wanli’s letters imported into DOCUSKY from MARKUS along with metadata on each letter. The textual database in DOCUSKY allows for the simultaneous use of user-supplied metadata (boxed here), tags (on the left; comments if included will show on the right), and natural keyword search for exploring the corpus. Personal name tags link to CBDB.
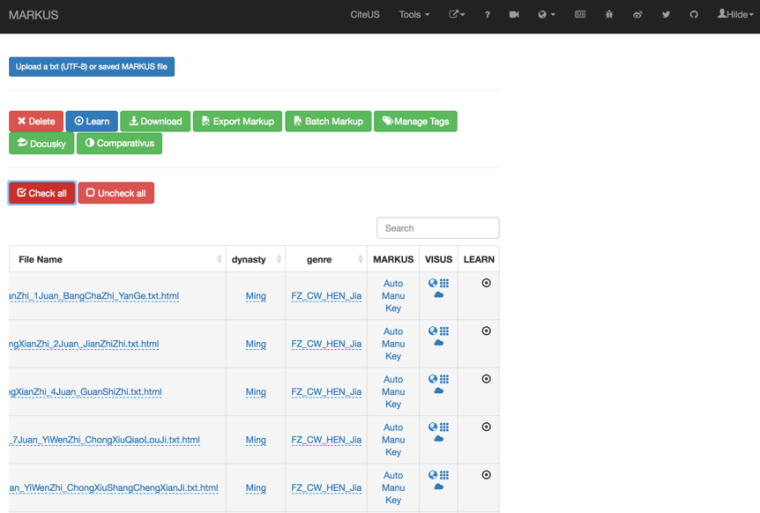
Figure 4B. MARKUS file management view. After setting up a free and private account, users can access saved files and select files for a range of operations.
MARKUS is thus designed and continues to be developed to model existing research flows, allowing for flexible switching between markup, reading, exploration, analysis, and annotation. I have learned much in the process of participating in this endeavor in a variety of ways. Participating in the design and implementation of research infrastructure increases one’s awareness of the strengths and weaknesses of digital media and methods and allows one to be critically and constructively engaged in their development and to contribute towards their improvement and alignment with humanities priorities. This experience also allowed me to see the importance of collaboration within academia and across sectors. Most of the added functionality and scheduled features come from the input and contributions from humanities researchers and students (such as relational markup which will allow for different types of relationships to be established between entities, text comparison in COMPARATIVUS (Mees Gelein, Hilde De Weerdt, and Brent Ho) which allows for the exploration, selection, and export of text overlap between texts (Figure 5), or machine learning (Miao Shengfa and Brent Ho) to improve the accuracy and recall of automated markup).
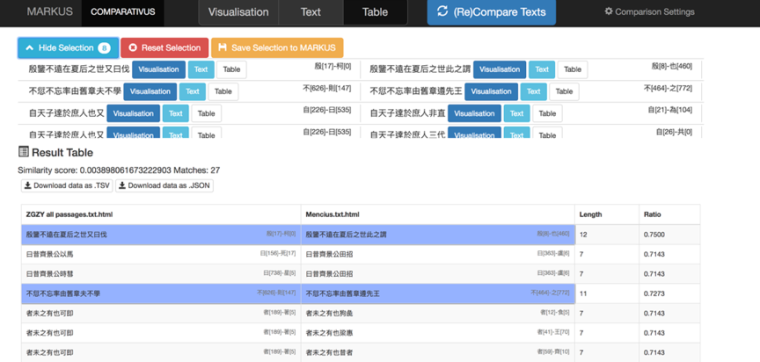
Figure 5. Comparison of text overlap between Zhenguan zhengyao and Mencius in COMPARATIVUS, showing selection from the table view for export to CSV and/or to the associated MARKUS files if the files were loaded into COMPARATIVUS from the MARKUS file management view (Figure 4B).
This kind of collaborative endeavor is not new in historical scholarship. In the first part of the twentieth century our predecessors in Tang and Song history compiled indexes, concordances, dictionaries, and other reference tools to facilitate their own work and that of others. In many ways developing digital tools is an extension and enrichment of these kinds of collaborative ventures, which have contributed significantly to the development of the field of Chinese history. We will need more of this if we want to ensure that the resources for which our institutions and we pay will be used well in the future. At the same time this engagement will present new challenges. Finding institutional solutions to keep services alive is but one of the many challenges that digital historians face. Developing curricula to ensure adequate training in humanities-specific computational methods, theoretical and critical approaches to digital media, as well as the critical assessment of both traditional and digital philological tools are also urgent tasks.
MICROSCALE TEXT ANNOTATION
In my experience so far, the investment of time in generalizing digital methods developed for one project pays off. It pays off when it gets taken up by others who work with it to make new findings in their own fields. It also pays off for the individual researcher. Following the completion of my work on notebooks, I started working on two microscale projects: a study of Yang Wanli and his correspondence and a translation and study of Zhenguan zhengyao. The former is part of comparative historical project aimed at juxtaposing the modes and effect of political participation by literati and clerics in Song China and medieval Europe mainly through a close reading of their correspondence. The latter started out as a collaborative effort to render this core text in Chinese political thought in English as part of the expanded Cambridge University Press series Texts in the History of Political Thought. The work we had already done on MARKUS has contributed in different ways to facilitating this work; the experience that tools can be modified to make them more suitable to the questions and needs at hand also inspired us to undertake further development to enable the kinds of microscale analysis that many historians are engaged in.
In order to gain a better grip on Yang Wanli’s letter collection, which includes nearly 500 pieces, I decided to combine more traditional note taking techniques with a multi-perspectival digital exploration of the text. I tagged all named entities in the letter titles and letters, but I also I added time and place of writing as well as the author’s position at the time to each letter title when this was known from modern editions and chronological biographies (nianpu). In addition to this metadata I also included the key themes addressed in the letter. In MARKUS I can convert this kind of annotation into a faceted overview of the collection and navigate through it by time, place, addressee, theme, places or people discussed in the letter, post of addressee or of the author, in maps, timelines, network views, tables, tag and word clouds etc. I can combine my data with those imported from CBDB to either gain total overviews, or to zero in on periods, themes, and letters that merit attention (Figures 4, 6-8—based on 250 letters). Some of this could have been done by compiling an excel sheet, but the combination of metadata, full text, and the broad range of visualization options make working this way far more flexible, and, time and again, has allowed me to modify impressions gained by unaided close reading. As partially evident in the figures some overall conclusions can be drawn about this corpus on this basis (the prominence of state councilors as addressees and the dominance of letters written from Jizhou to the capital, for example), but as this work is still ongoing it is here mainly adduced to demonstrate the methodological and philological strengths of this approach.
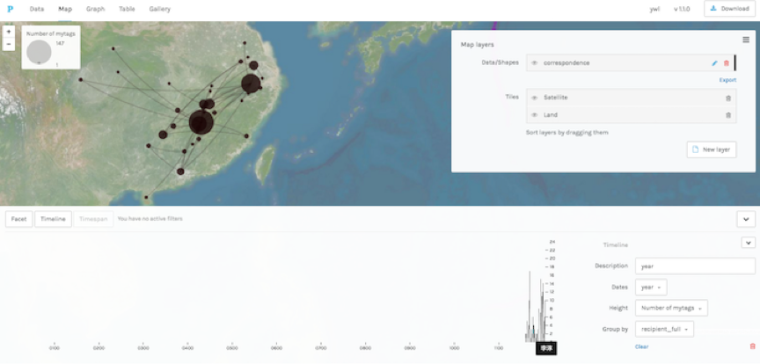
Figure 6: Map and timeline overview in Palladio of the correspondence of Yang Wanli (sample of 250 letters) tagged in and exported from VISUS interface in MARKUS (Figure 4B).
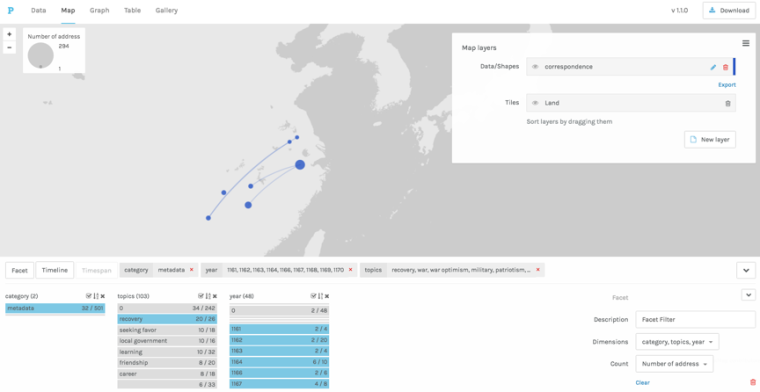
Figure 7: Faceted browsing in the map view of Palladio of the correspondence of Yang Wanli (sample of 250 letters) tagged in and exported from VISUS (Figure 4B).
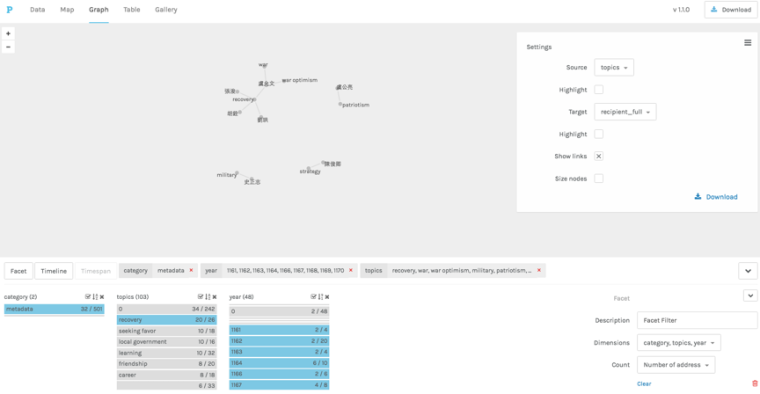
Figure 8: Faceted browsing in the network view of Palladio of the correspondence of Yang Wanli (sample of 250 letters) tagged in and exported from VISUS (Figure 4B).
In our translation of Zhenguan zhengyao we are employing tagging for yet different, mainly editorial, purposes. We tagged the entire texts to generate the kinds of standardization tools that joint translations require: lists of official titles and indexes of place names, personal names, and book titles. Readers will also be able to use this file, however, to quickly retrieve passages based on these criteria and others they might want to add (such as text reuse tags generated through COMPARATIVUS as shown in Figure 5). We are also developing a flexible digital edition that will allow readers to read the text in more ways than the standard layout: passages can be aligned according to chronological sequence for instance, or rearranged according to their sequence in different editions.
There are plenty of unintended consequences and surprise finds in digital research and working digitally may spiral into further investments in shaping the digital philological methods of the future. After having manually tagged the names of informants in Wang Mingqing’s Huizhu lu, for example, I continued to tag all personal names in it in order to see what this would reveal about who was mentioned most frequently, who was mentioned by whom, who was mentioned with what other historical figures, etc. Using different ways of measuring the centrality of those mentioned in the text, I could corroborate some of what I had suspected (the centrality of Cai Jing, for example), confirm less obvious tendencies in the text (the centrality of Zeng Bu and Gaozong), and also uncover how sentiments attached to central figures can be explored (not only through terminology but also through clustering and the dependencies of some actors on others). Such finds can lead to new algorithms for detecting bias in larger corpora of texts and help historians make decisions about what texts to include in their analyses and how to place them in their larger intellectual and political context.
IN CONCLUSION
I hope to have suggested in my comments above that digital methods are suitable for a wide spectrum of historical research projects, ranging from the close reading of particular texts and the exploration and analysis of larger corpora to the extraction and mapping of data from tens of thousands of documents. Digital analyses need not lead back to quantitative history exclusively; we can now accomplish different kinds of historical writing with them. We can help uncover the structure and knowledge embedded in historical texts and objects with digital methods--as in the case of one of my first GIS projects which was aimed at reconstructing the reading instructions that accompanied one of the first printed maps of the Chinese territories. We can experiment with social scientific history using network analysis, sampling, and probabilistic methods to test prior conclusions, raise new questions, highlight lacunae in prior scholarship, and propose new explanations. And we can continue to develop and work with philological tools that build on and strengthen those that have laid the foundation of historical scholarship in early modern and modern times.
NOTE
For this piece I was invited to contribute my thoughts on historical practice and computing based on my own work. The following explore the thoughts articulated here further:
BLOGPOSTS:
Collaborative Innovation and the Chinese (Digital) Humanities. University of Nottingham China Policy Institute Blog, June 9, 2016, https://blogs.nottingham.ac.uk/chinapolicyinstitute/2016/06/09/collaborative-innovation-and-the-chinese-digital-humanities/
Isn't the Siku quanshu enough? Reflections on the impact of new digital tools for classical Chinese. Communication and Empire: Chinese Empires in Comparative Perspective, Feb. 20, 2014, http://chinese-empires.eu/blog/isnt-the-siku-quanshu-enough-reflections-on-the-impact-of-new-digital-tools-for-classical-chinese/
Digital Interpretations. Communication and Empire: Chinese Empires in Comparative Perspective, Feb. 5, 2014, http://chinese-empires.eu/blog/digital-interpretations/
INTERACTIVE READING PLATFORM
Information, Territory, and Networks: The Crisis and Maintenance of Empire in Song China--Accompanying data and visualization site. 2015. http://chinese-empires.eu/reference/information-territory-and-networks/
PODCAST
“Hilde De Weerdt on MARKUS.” 7/31/2016. DH East Asia Podcast. http://www.dheastasia.org/2016/07/31/podcast-3-hilde-de-weerdt-on-markus/
SOFTWARE
MARKUS: A markup, reading, and visualization platform for classical Chinese texts (with Brent Ho) 2014- http://dh.chinese-empires.eu/beta/
MARKUS instructional videos. https://dh.chinese-empires.eu/markus/beta/video.html (English) https://dh.chinese-empires.eu/markus/beta/video_zhtw.html (traditional Chinese) https://dh.chinese-empires.eu/markus/beta/video_zhcn.html (simplified Chinese) 2014-
COMPARATIVUS: A text comparison platform (with Mees Gelein, Brent Ho)
http://dh.chinese-empires.eu/comparativus/
Tu Hsieh-Chang, Hsiang Jieh et al. Docusky. http://docusky.digital.ntu.edu.tw/ Instruction manual (inc. basic MARKUS instructions):
https://docusky.digital.ntu.edu.tw/DocuSky/ds-11.instructions.html
VIDEOS
Digital Perspectives on Middle-Period Political History. 4/5/2016. University of Michigan, Ann Arbor, Lieberthal-Rogel Center for Chinese Studies. https://youtu.be/2oxHTEFEa38 (different versions of this talk: Gothenburg http://media.hum.gu.se/filedb/index.php?cdir=TmpVNU1qZz0%3D&c_hash=62c1644730fcf46086164dc08fdcf5e8 and http://media.hum.gu.se/filedb/?cdir=TmpVNU1qYz0%3D&c_hash=41c9fba5f4490c7c0501ac047752a02b and Stanford https://vimeo.com/168242706 )
Humanities Tools for Library Resources. 4/4/2016. University of Michigan, Ann Arbor, University Library. http://leccap.engin.umich.edu/leccap/viewer/r/azO7QY
文本標記與歷史研究 (Textual Markup and Historical Research). 4/29/2015. Academia Sinica, The Institute of History and Philology, Taipei https://www.youtube.com/watch?v=NltG3EjC9_A
宋代新資訊結構的形成 (The Development of a New Information Regime in Twelfth-Century Song China) 4/27/2015. National Taiwan University, Chinese Department, Taipei https://www.youtube.com/watch?v=1Xd_mJ9eJHk