-
X Xiongposted in Research blogs • read more
Recently, I have been using MARKUS to explore information on city walls due to my participation in a project, the History of Chinese City Walls (1000-1900), organized by Professor Hilde De Weerdt with Jialong Liu’s collaboration at the Leiden University Institute for Area Studies. This project uses a digital approach to investigate the history of construction in imperial China. The main source materials for this project are Chinese local gazetteers. Most of these local gazetteers contain information on the geography, history, local government, infrastructure, products, people, literature, etc. of a particular region. These categories of information are often organized by listing items and describing them in regular linguistic patterns. We can, therefore, use the “regular expression markup” function in MARKUS to identify information about local construction in gazetteers.
To use the “regular expression markup” function the most significant step is to identify which patterns are used in the texts we would like to work with. If we regard “keywords” as characters, terms, phrases that appear in a fixed sequence, then “regular expressions” can be perceived as a sequence of characters, terms, phrases that specify a search pattern. In our construction project, we first conducted a pilot study to generate preliminary tag sets of keywords and regular expressions based on a close reading of inscriptions commemorating the construction or repair of city walls in the extant Song-Yuan local gazetteers and a small number of Ming gazetteers selected at random.
Let’s take a look at how we generated a list of regular expressions to describe the scale of the features of city walls. We first identified patterns appearing in the sample texts.

Then, we compiled a preliminary set of regular expressions based on the detected patterns. The basic symbols used to compile regular expressions were as follows:

The compilation of regular expressions began with identifying the character sets used to describe wall facilities:

Then, we identified the frequency with which the character set could appear and combined the character set and the frequency into one component of the regular expression.

Subsequently, we compiled the next component of the regular expression of the scale of wall facilities:

Next, we assembled all components together as one regular expression. An important tip when using regular expressions in MARKUS is to add one more parenthesis to enclose all components in order to turn them into one set:

After completing all the above steps, we inserted the complete regular expression into the MARKUS keyword markup module. To learn how this works, watch the tutorial video on “pattern markup.”
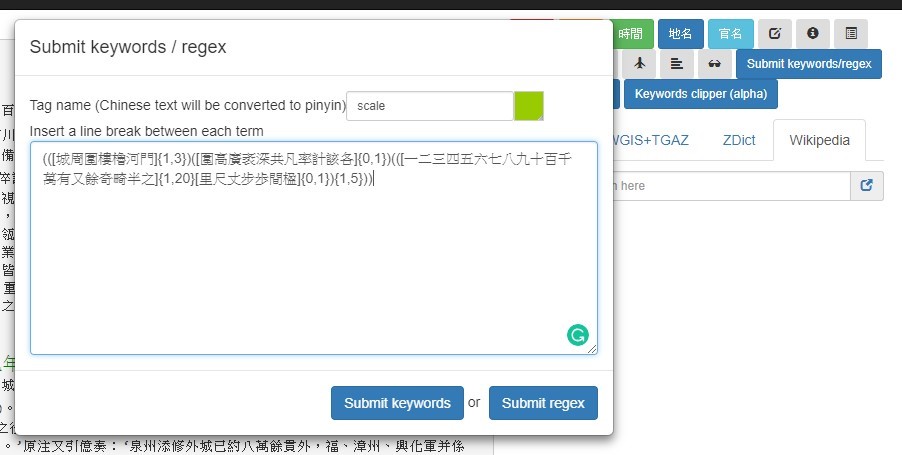
MARKUS will first show the number of results found in the selected text.
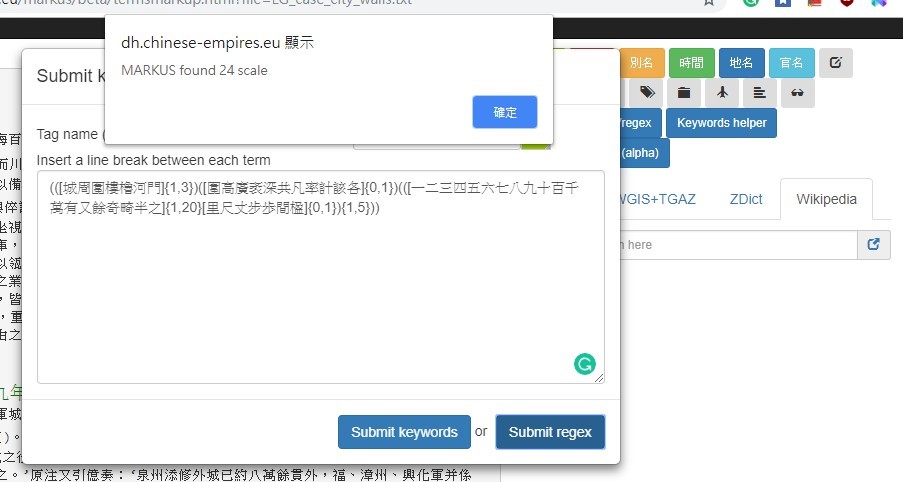
Click “confirm 確定”, and all results will have been tagged and will show in the chosen color. All results can be exported into an xls or cvs file for further analysis.

Regular expressions are a practical means for exploring and retrieving data which appear in well-defined patterns. MARKUS users can also use regular expressions in Batch-markup. This function allows users to annotate multiple tags in multiple texts at once. For example, we can insert four sets of regular expressions to search for information on length, height, thickness, budget, etc. of city walls in selected texts at the same time.
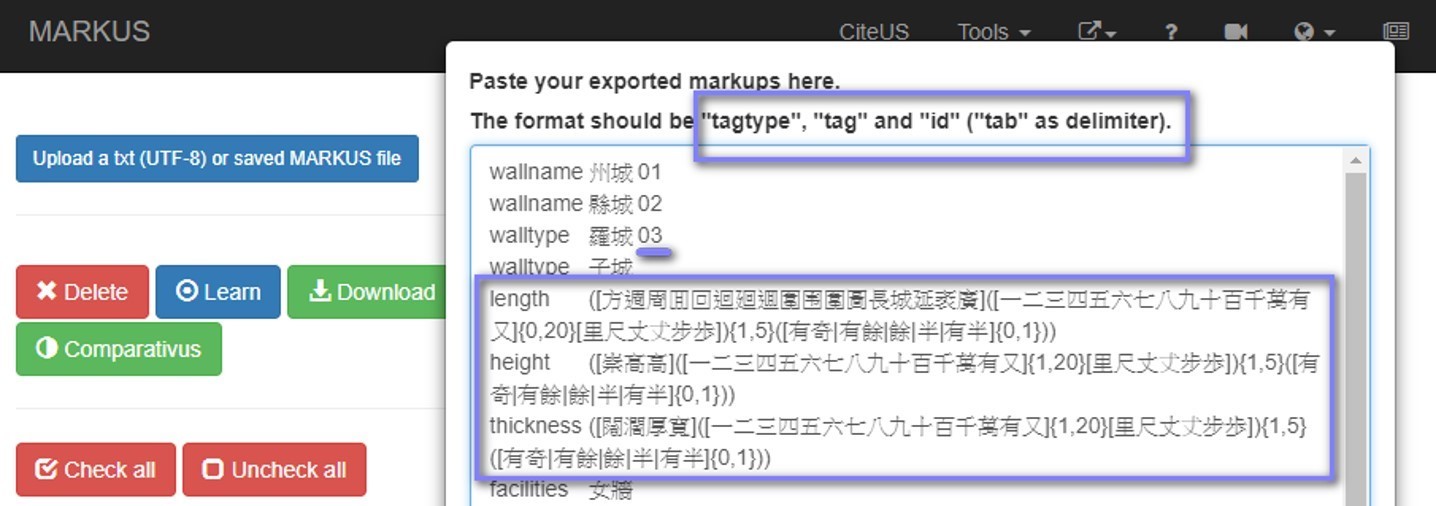
Then, MARKUS will tag all detected results as shown in the picture below. To learn how to use this function, watch the tutorial on Batch-markup.
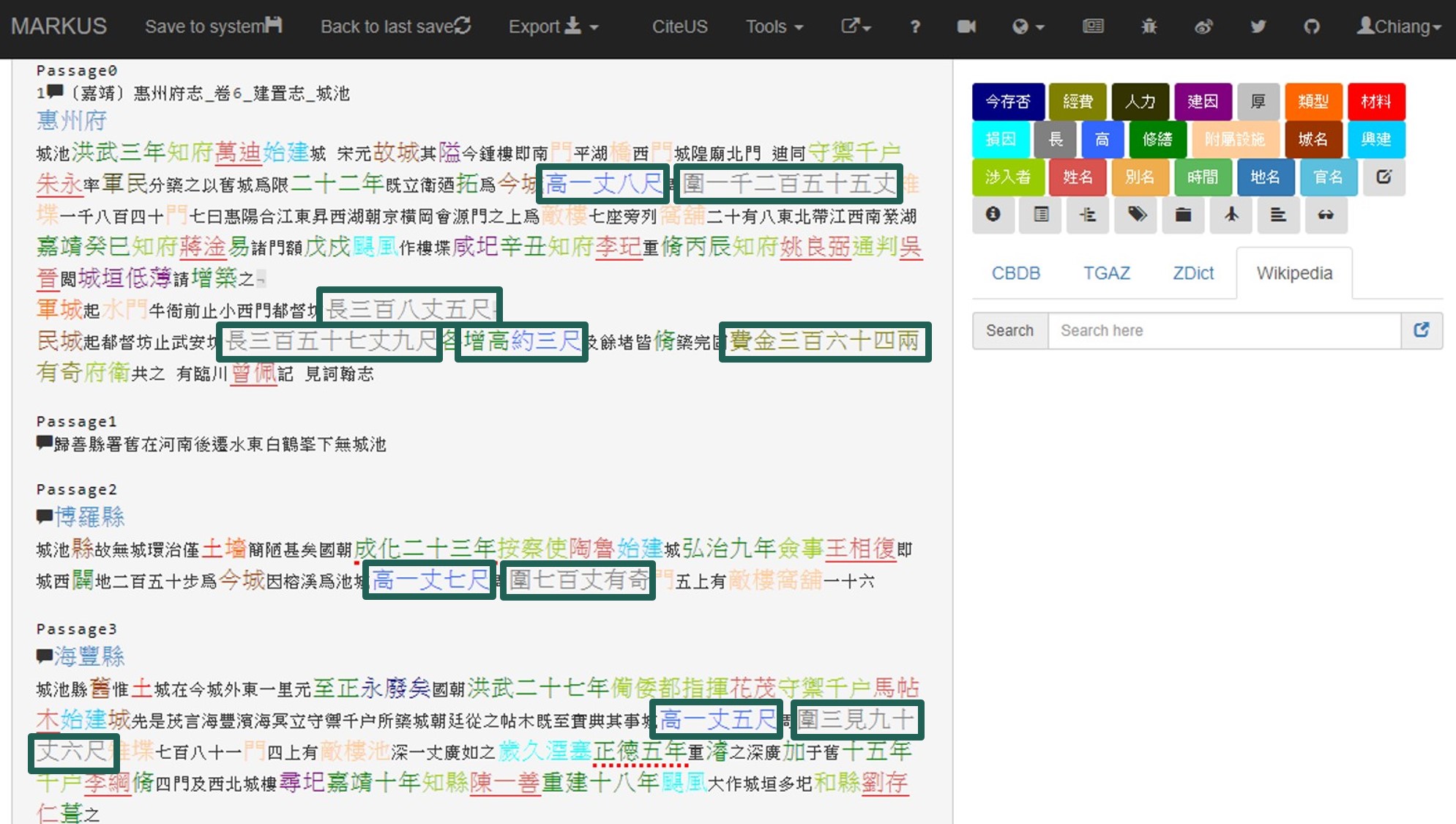
Nowadays, a relatively large number of titles of Chinese local gazetteers has already been digitized. This allows users to apply regular expressions to exploring the data in gazetteers. However, some challenges still exist. One challenge is to balance specificity and vagueness in the compilation of regular expressions. For instance, it is possible to use a rather vague regular expression in order to search for all strings of numbers and measure units in gazetteer texts. However, the ensuing step of data-cleaning may thus become quite time-consuming filtering irrelevant information. By contrast, regular expressions that are too specific may result in the omission of targeted information that appears in a similar but more variegated pattern. The key to finding balance highly depends on the research questions and the scale of a given project.
Another challenge is to work with the variants of Chinese characters in the digitalized gazetteer corpus. Variants of a given character may exist in original texts, originated from gazetteer compilers’ choices or preferences. Character variants may also appear during the process of digitalization, such as OCR or coding. Take the character “高” (gao height), for example. Besides its most common variant 高, this character also has variants as
 If we do not take these into account when compiling regular expressions, it is likely that relevant information will be omitted in the search results. To tackle this issue, we can first collect variants via close reading while identifying string patterns and later supplement desired but neglected variants into the current regular expressions during data-cleaning. However, a more effective way is to consult variant collections or dictionaries for characters that can be anticipated to appear in texts and insert the variant collections into the regular expressions.
If we do not take these into account when compiling regular expressions, it is likely that relevant information will be omitted in the search results. To tackle this issue, we can first collect variants via close reading while identifying string patterns and later supplement desired but neglected variants into the current regular expressions during data-cleaning. However, a more effective way is to consult variant collections or dictionaries for characters that can be anticipated to appear in texts and insert the variant collections into the regular expressions.Exploring data in Chinese local gazetteers with regular expressions is often based on trial and error. The more we grasp the features of targeted texts and the subtleties of regular expressions, the more effective our search for the desired information will be.