-
H hu777jingposted in Announcements • read more
MARKUS is of good compatibility and expansibility in terms of supporting multilingual interfaces. This feature allows developers to extend it into other languages easily. The development of the Korean version of MARKUS (hereafter referred to as K-MARKUS) is the first systematic attempt to adapt the model to another language. We conducted the project in 2017-2019, led by Prof. Hilde De Weerdt at Leiden University and in collaboration with the Institute of Traditional Culture in South Korea.
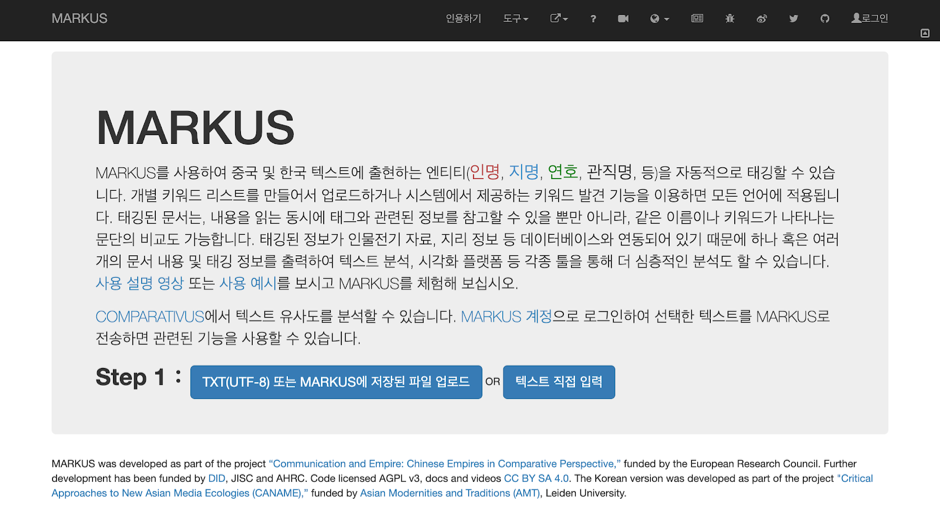 Figure 1: Screenshot of the Front Page of K-MARKUS
Figure 1: Screenshot of the Front Page of K-MARKUSThe development of the Korean version hinged on the adoption of databases developed in South Korea. The evaluation of available Korean historical data was the first step of the project. Based on our earlier research on the status of the field relating to Korean data, we understand that although there are abundant Korean historical data on a wide range of topics, those datasets are scattered and held by different organizations. In order to link the disparate datasets to the MARKUS platform, we built a partnership with the Institute of Traditional Culture, which we asked to integrate the datasets and create APIs to provide access to the aggregated data. This way, we were able to fetch the Korean data through the APIs provided by the Korean end, instead of tackling with the miscellaneous data as remote developers.
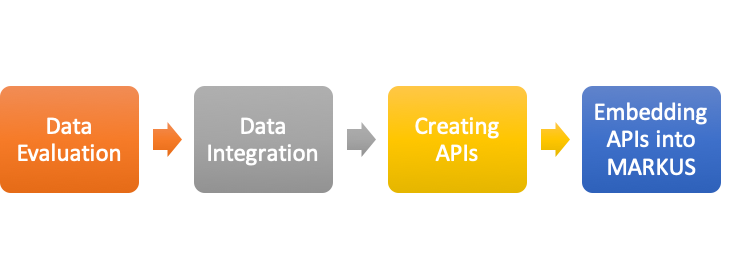
Figure 2: The process of how K-MARKUS fetches Korean data.After evaluating the most relevant and available Korean datasets on their accessibility, feasibility, quality, and compatibility, we decided to first implement automated tagging and identification of Korean personal names, places names, bureaucratic titles and books in K-MARKUS. In accordance with the named entity types, we retrieved 9 datasets from 6 databases held by different Korean organizations including the Academy of Korean Studies, the Institute for the Translation of Korean Classics and the National Institute of Korean History. As seen in Figure 3, each type of Korean named entities contains a number of datasets from different databases. In order to unify these heterogeneous databases into the framework of K-MARKUS, we tailored new database schemas according to each entity type, and created 4 independent APIs to access the corresponding data.
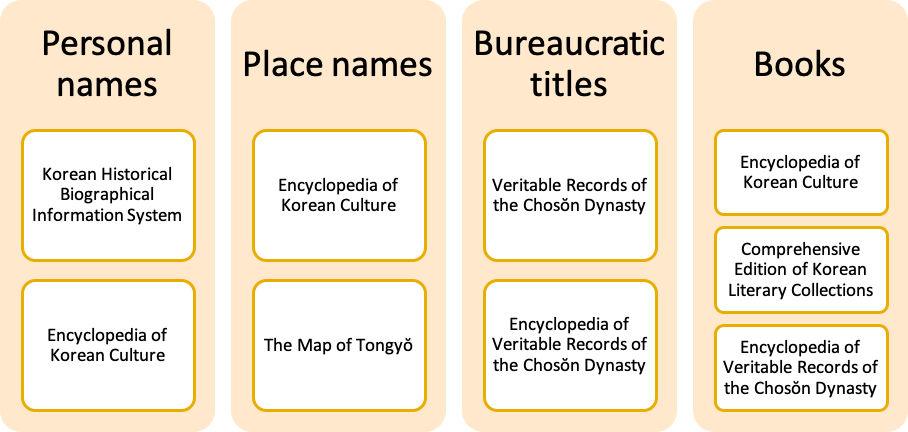
Figure 3: The four types of named entities in K-MARKUS and their data sourcesIn general, K-MARKUS maintains the major functionalities of the original version, such as the automated and manual mark-up of default named entities and user-generated tags, keyword discovery, batch mark-up, linked reference materials, data curation, content filtering, data export, as well as the associated textual analysis platforms and data visualization platforms linked with MARKUS. As demonstrated in Figure 4, users can start the automated tagging function by selecting Korean named entities in the markup options under the automated markup module.
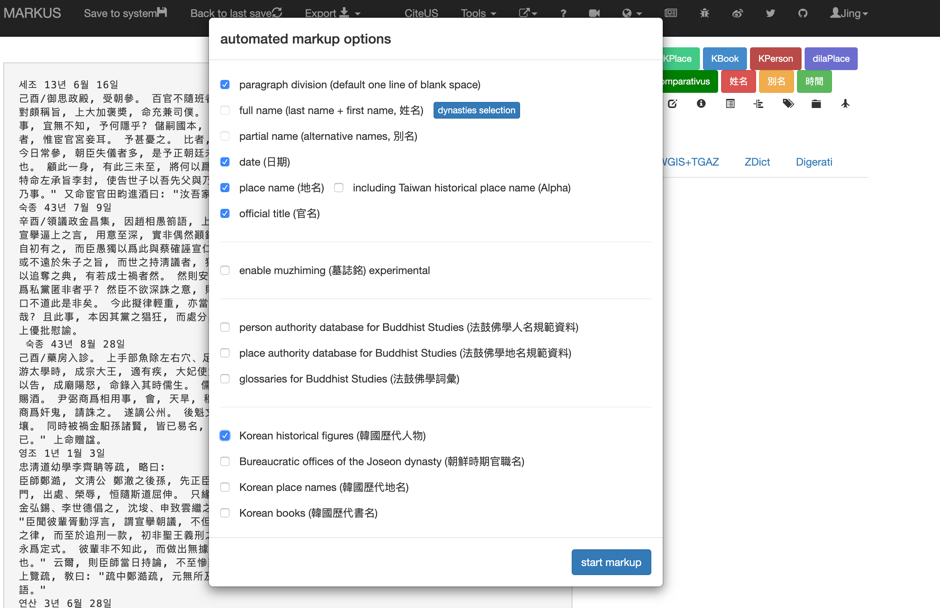 Figure 4: Screenshot of implementing the automated markup function by selecting the Korean entities in the pop-up window of “automated markup options”.
Figure 4: Screenshot of implementing the automated markup function by selecting the Korean entities in the pop-up window of “automated markup options”.Given that Korean historical data is well interlinked with each other, K-MARKUS also takes advantage of this feature and provides users with references to various external websites including historical maps, biographical databases, encyclopaedias, and historical text databases. For instance, users can check a Korean place in the Tongyŏdo historical map by clicking the link provided by the reference window, and examine its geographical features by zooming in and out. More importantly, as the Tongyŏdo map is linked to diverse digital archives preserving primary sources relating to each place, such as documents (e.g. gazetteers, official documents, slave-trade contracts, household registration document), figures, and events, users can access the historical sources through the entries on the digital map (see Figure 5).
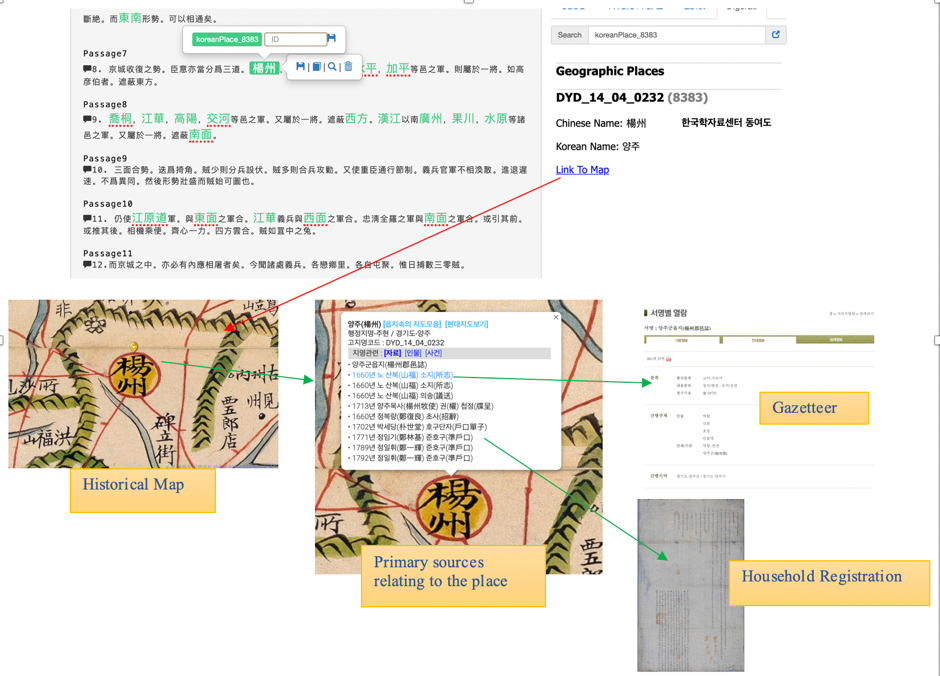 Figure 5: Web reference for the Korean place Yangju (楊州) in K-MARKUS and linked primary sources relating to Yangju in different digital archives.
Figure 5: Web reference for the Korean place Yangju (楊州) in K-MARKUS and linked primary sources relating to Yangju in different digital archives.Figure 6 demonstrates how the K-MARKUS platform provides web references to the Korean book T'oegyejip (退溪集, “Collected works of Yi Hwang”). The Dictionary of Digerati offers two references for the book by providing a link to the bibliographic information in the Collection of Korean Literature and a link to the Encyclopedia of Veritable Records of the Chosŏn Dynasty. Users can also access the full text of the book as the bibliographic information includes a link to the full text.
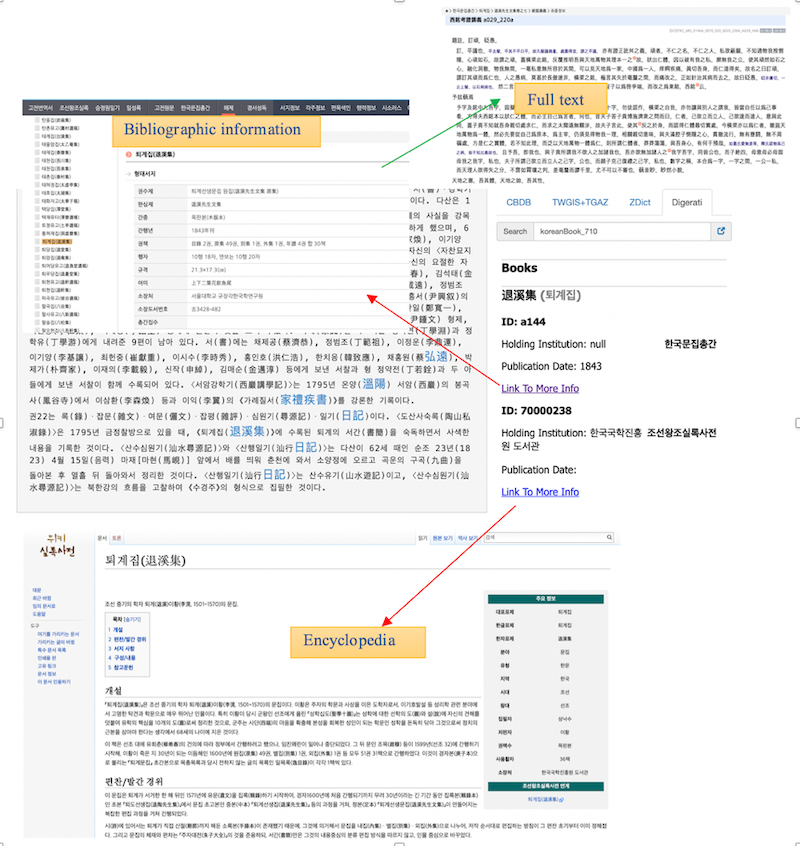 Figure 6: The web references for the Korean book T'oegyejip and linked full-text.
Figure 6: The web references for the Korean book T'oegyejip and linked full-text.In the same vein as the books, reference information for bureaucratic titles is also linked to the Veritable Records of the Chosŏn Dynasty (Chosŏn wangjo shillok 朝鮮王朝實錄). Users can check sources relating to the bureaucratic title in the Veritable Records of the Chosŏn Dynasty by selecting the date of the record (see Figure 7).
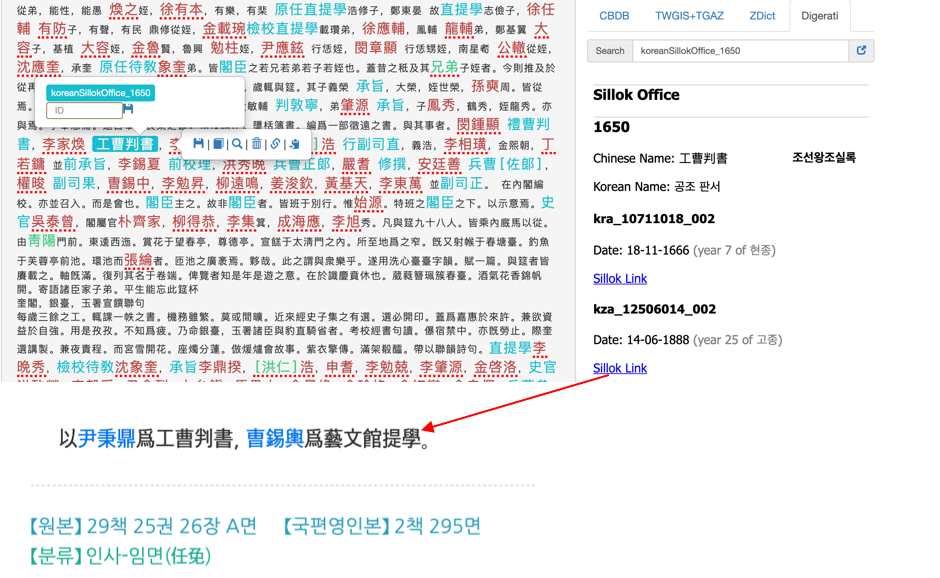 Figure 7: The web references for the Korean official title Kongjop'ansŏ (工曹判書, “Minister of Works”)
Figure 7: The web references for the Korean official title Kongjop'ansŏ (工曹判書, “Minister of Works”)As mentioned above, other functionality such as the manual markup, keyword markup, passage filter and Comparativus work equally well for Korean texts. Figure 8 is an example of using the “keywords helper” function to retrieve all the accommodation spots in Pak Chiwŏn’s Yŏrhailgii (熱河日記, “Diary to Rehe”).
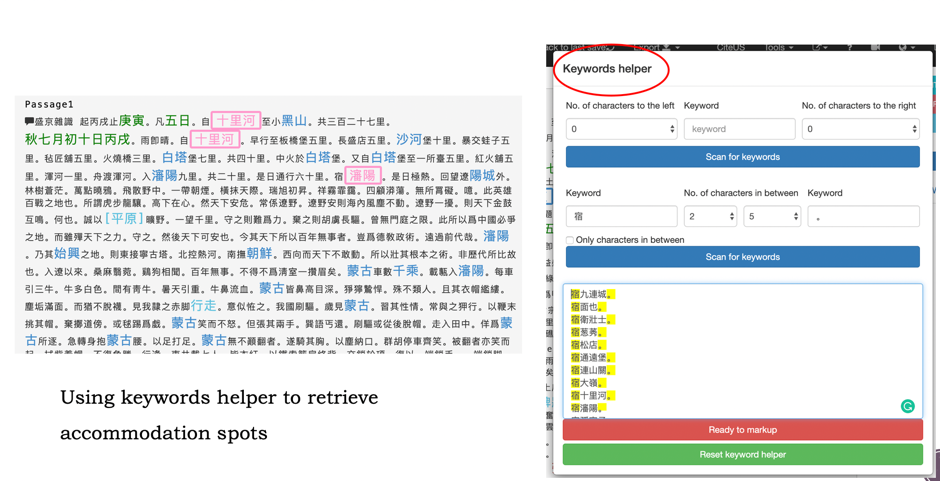 Figure 8: Using the Keywords helper in the keyword markup module to retrieve place names from Korean texts (Yŏrhailgi by Pak Chi-Wŏn)
Figure 8: Using the Keywords helper in the keyword markup module to retrieve place names from Korean texts (Yŏrhailgi by Pak Chi-Wŏn)Figure 9 demonstrates using Comparativus to compare two envoys’ travelogues written in the 18th century – Hong Daeyong’s Tamhŏnsŏ (湛軒書, “Collection of works by Hong Daeyong”) and Pak Chiwŏn’s Yŏrhailgii.
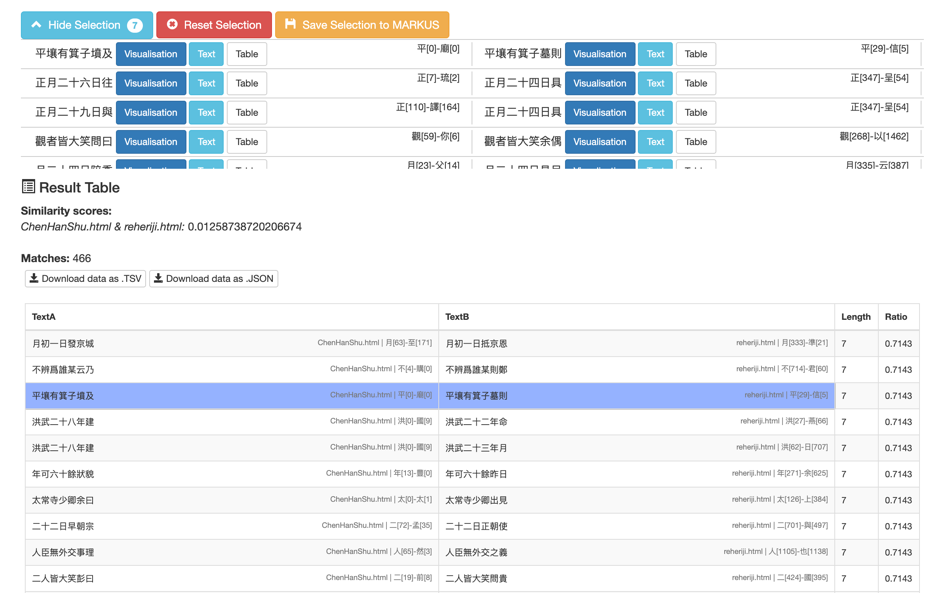 Figure 9: Using the Comparativus to compare Korean texts -- Tamhŏnsŏ and Yŏrhailgi.
Figure 9: Using the Comparativus to compare Korean texts -- Tamhŏnsŏ and Yŏrhailgi.Users can also export the tagged Korean texts to associated research platforms with MARKUS such as Docusky.
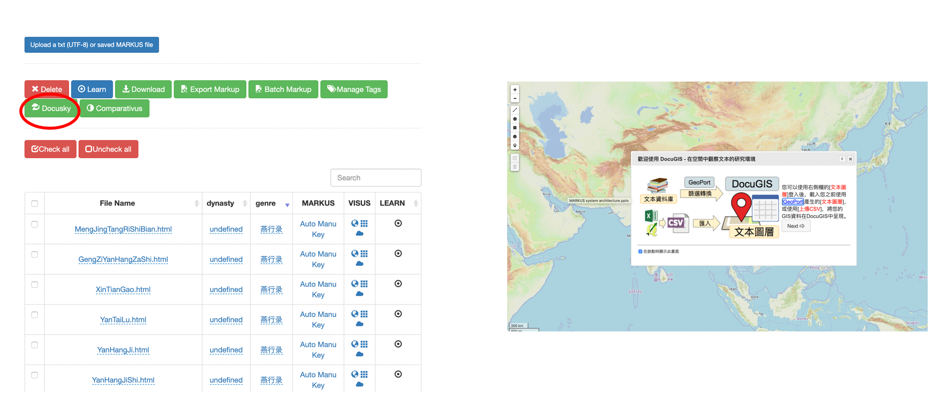
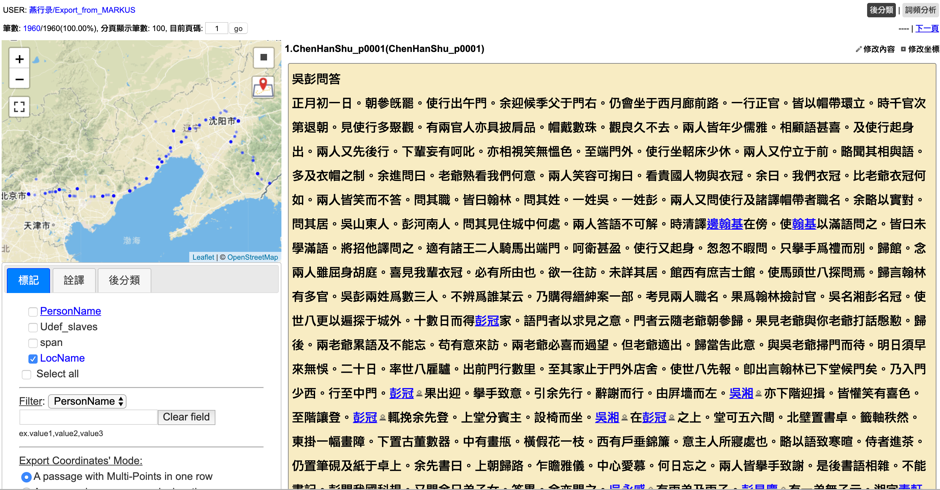 Figure 10: Exporting tagged Korean texts to associated platform (Docusky).
Figure 10: Exporting tagged Korean texts to associated platform (Docusky).As the first attempt to extend MARKUS into another language, we prioritized the automated mark-up of Korean personal names, place names, bureaucratic offices and book titles in K-MARKUS. Nevertheless, there are tasks remaining as well. For instance, given that there is a wide variety of datasets on Korean historical events and cultural heritages, we hope we can structure these data and adopt them into K-MARKUS in the near future. Also, in view of the accessibility of Korean full-text data, K-MARKUS could include an “open access text lookup” function as well – which enables users to look up and access the full text from open access sources and automatically input the digital text to the K-MARKUS interface.!