In 2015, I started using MARKUS to mark up textual passages that I had to translate for my MA thesis. The built-in ability to identify place names, official titles, personal and alternative names, reign periods, and its easy-to-use interface make it one of the best online platforms for Sinologists who rely on texts in Classical Chinese. While the identification is not always spot on – you still need to use your brain – the identification errors can be easily spotted and manually corrected. And it’s not as time-consuming as tagging everything manually. Since last summer I have been working on a new research project about Tang emperors and have been using a few specific functions in MARKUS to select the passages that I want to analyse. In this blog, I want to share my most recent experiences with manual tagging. At the moment I am collecting direct speech quotes from emperors in a text I am familiar with, the Tang guoshi bu 唐國史補 [Supplement to the History of the Tang]. I could read the text line by line and make notes along the way, but this is very time-consuming. With the use of MARKUS, I can easily filter textual passages with direct speech quotes that are useful for my research, and skip the ones that are not useful because they do not contain speech quotes. Finally, I will export the results to Excel to do further analysis. To search for all the direct speech quotes in a text I have made use of the ‘Keywords helper’ function in MARKUS. With the ‘Keywords helper’ function, MARKUS can tag keywords or characters between certain keywords or characters. Since my text is punctuated, I can easily search for quotations by scanning for double quotation marks (『』). Everything between these two marks should be a quotation (if your text is punctuated, but does not include quotation marks, you can still search for other characters [e.g. 曰 and。]). I have set the minimum of characters to 1 to include even the smallest quotations.

After hitting ‘Ready to markup’ I tagged these keywords (quotes) under a new tag name by clicking on ‘Submit keywords’.
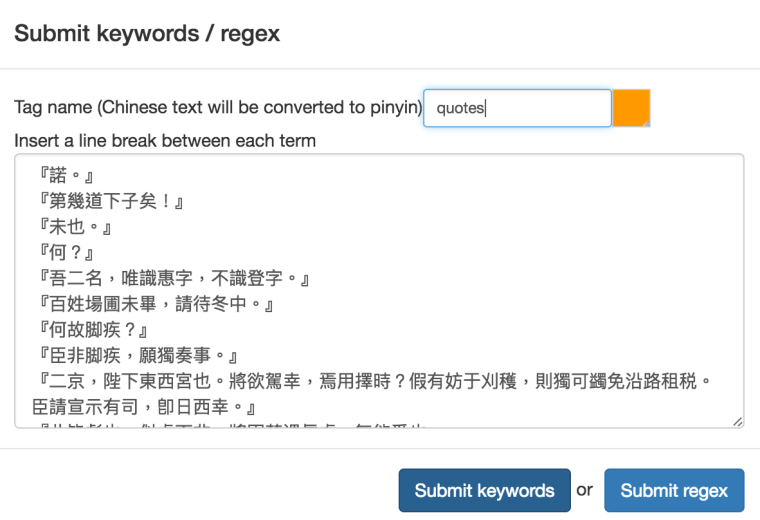
This is the result when only the newly created tag ‘quotes’ is visible:

Since I have also tagged personal names, it is now easy to select only the passages in which certain emperors are mentioned with the ‘passage selection’ function. For this example I selected only one specific id: 19244 (Emperor Xuanzong), but it is also possible to select multiple ids.
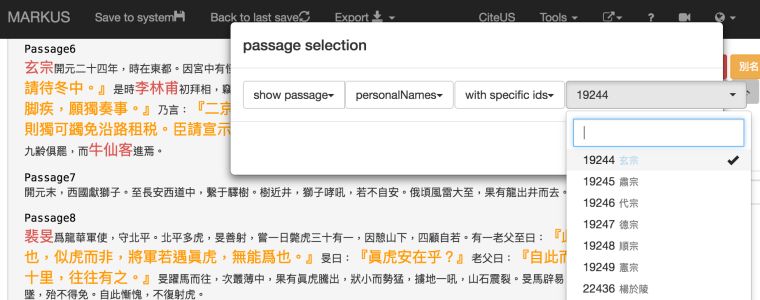
After clicking on ‘filter’ only the passages with the specific id of Emperor Xuanzong (in a slightly bigger font size) are shown:

In manual mode, I identified the direct speech quotes from Xuanzong by giving the tag-id the name of the person who is speaking:

I did the same for quotes from other Tang emperors in this text (Daizong 代宗, Dezong 德宗, and Huizong 憲宗). I then exported all the tags to Excel by clicking on the ‘tag summary’ button. I chose to include 10 characters before and after each tag to include information about who is speaking before I clicked on ‘XLSX (MS Excel, testing)’.
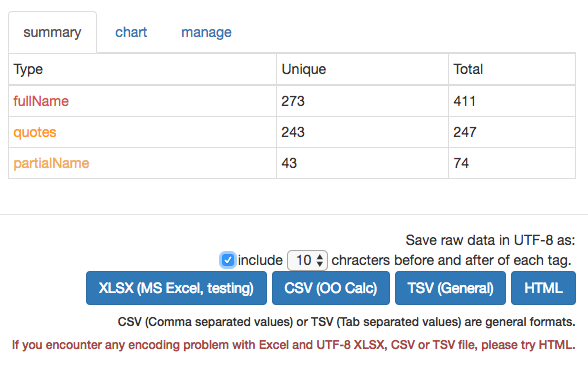
In Excel, the results after sorting on type (column B ) and id (column C) are as follows:
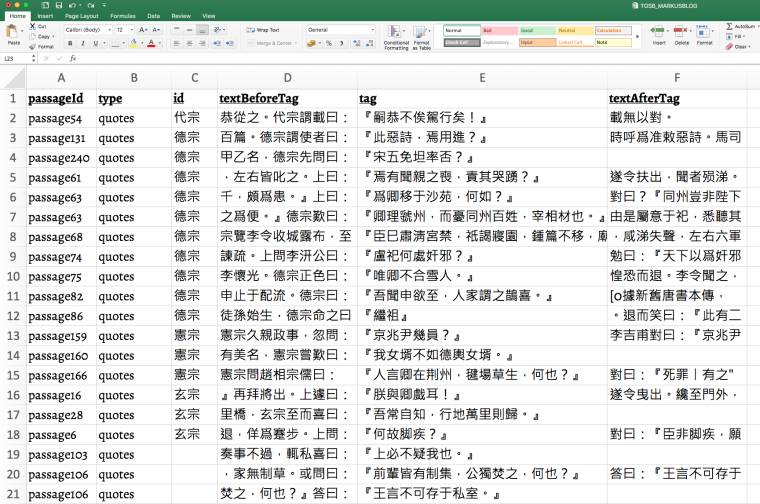
With MARKUS, I was able to quickly search all the direct speech quotes, filter all the quotations and manually ID the quotes. Ultimately the tags were exported to Excel. Now the same can be done for other texts for further analysis and comparison.